

ブログ

最新情報をお届けします。

「Snowflake」と「Tableau」の連携
著者:Craig Cullum
原文:https://www.knime.com/blog/will_they_blend_snowflake_meets_tableau
「Snowflake」はクラウド型データウェアハウスのSaaSで、「Azure」や「AWS」にグローバルにデプロイできます。また、パフォーマンスとコストの両面でスケーリングできる柔軟性があり、ユーザーがデータベースを使用していないときに自動的にオフにし、急激に負荷の増加に対応して自動的にスケールアップしパフォーマンスを確保することができます。
[KNIME」を「Snowflake」に接続することで、エンタープライズに対応した高機能なクラウド型データウェアハウスをすぐに作成できます。また、市場をリードするBIツールと連携することができます。
目次
「Snowflake」と「Tableau」の連携
「Snowflake」に接続するレポートツールとして、多くの企業でBIツールとして採用されている「Tableau」を使ってみます。「Tableau Desktop」は商用ライセンスが必要です。
「Tableau」と「Snowflake」はどちらも試用することができます。「KNIME」はTableau形式でデータを保存できる「Tableau Writer extension」をサポートしています。TDE形式および、.Hyper形式でデータを直接Tableau Serverに公開することもできます。
「KNIME」はお客様のビジネスに最適なクラウド内データウェアハウスやビジネスインテリジェンスパッケージを選択できる柔軟性があります。
ワークフロー例について説明します。このワークフローでは、「Snowflake」インスタンスでExcelの売上データを毎日取り込み、REST APIを介してダウンロードされたJSON形式のオンラインeコマースプラットフォームから提供されたすべての返品を除外します。
次に、日次データのサブセットが.Hyper形式ファイルにエクスポートされ、最終レポートが作成されます。
- トピック
クラウド内のデータウェアハウス(DWH)を作成します。 - チャレンジ
DWHワークフローを作成して売上データを「Snowflake」にインポートします。このデータをREST APIからJSONフォーマットでe-commerceプラットフォームからの戻り情報とマージし「Tableau」でレポートを作成します。 - アクセスモード/統合ツール
Snowflake & Tableau
実験
この実験のために以下が必要です。
- 「Tableau」の試用版またはライセンス版
- 体験版またはライセンスを受けた「Snowflake」インスタンス
- 「Snowflake」のJDBCドライバ
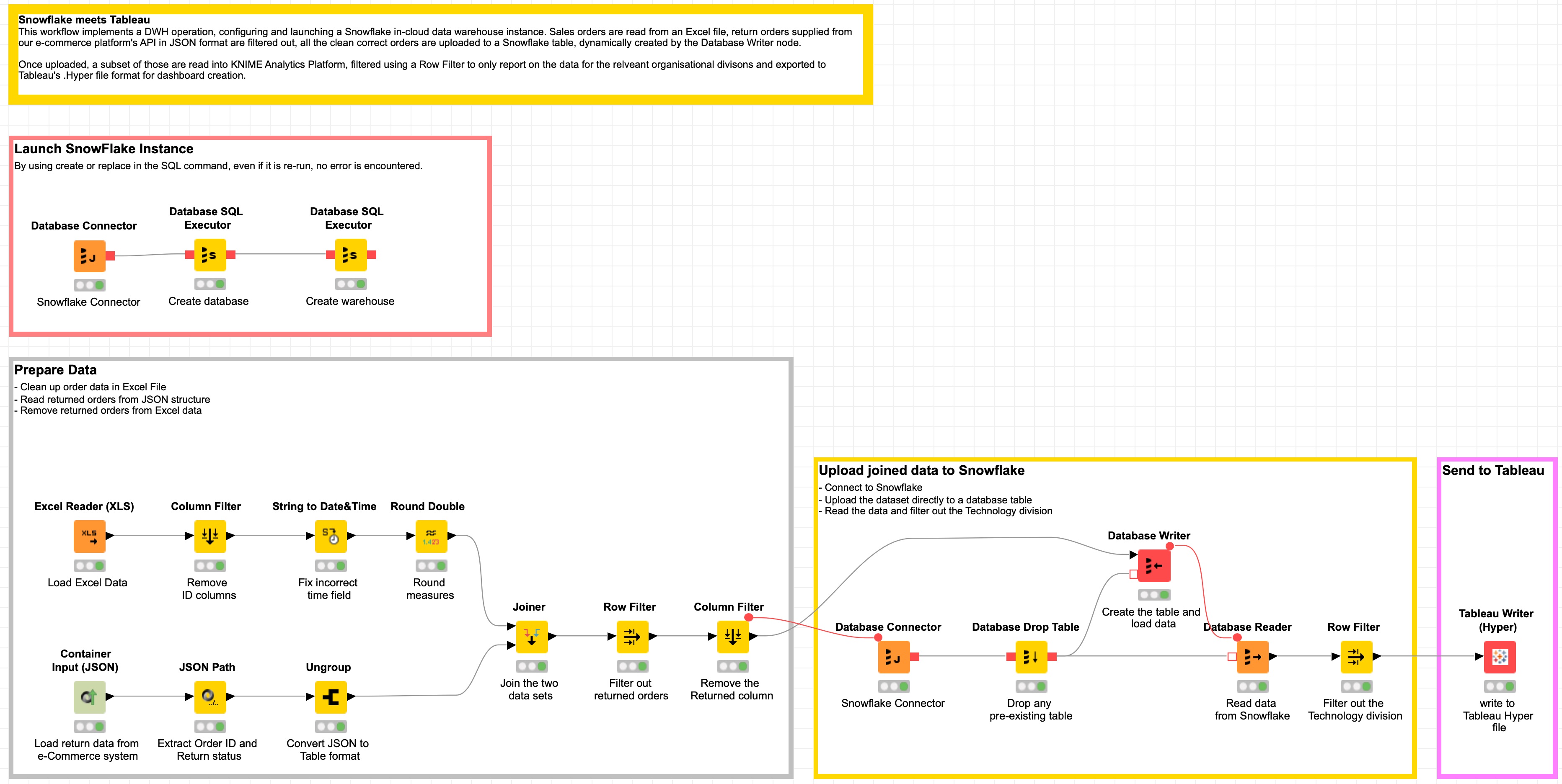
図1:KNIMEワークフロー-「Snowflake」と「Tableau」の組み合わせ
「Snowflake」のJDBCドライバのインストールと設定
「Snowflake」を使って「KNIME」で何かをする前に、まず「Snowflake」のJDBCドライバをダウンロードしてインストールする必要があります。
1.Maven経由で「Snowflake」のWebサイトからJDBCドライバをダウンロードし、削除しない永続的なディレクトリに保存します。
必要なのはJavadocではなくjarファイルです。
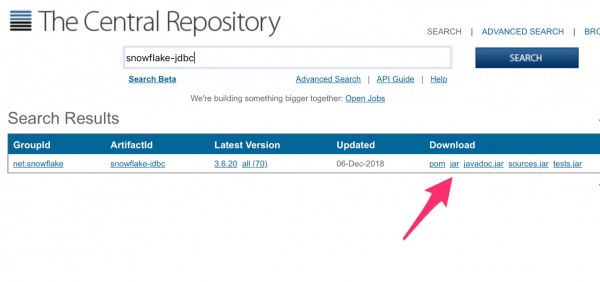
図2:JDBCドライバーを保存する
2.「KNIME」を開き、[File]→[Preferences]に移動します。画面はApple Macの例です。
3.[KNIME]セクションを展開し、[Databases]を選択します。
次に、[Add file]をクリックし、前のステップでダウンロードしたJDBCドライバ(.jarファイル)を登録します。
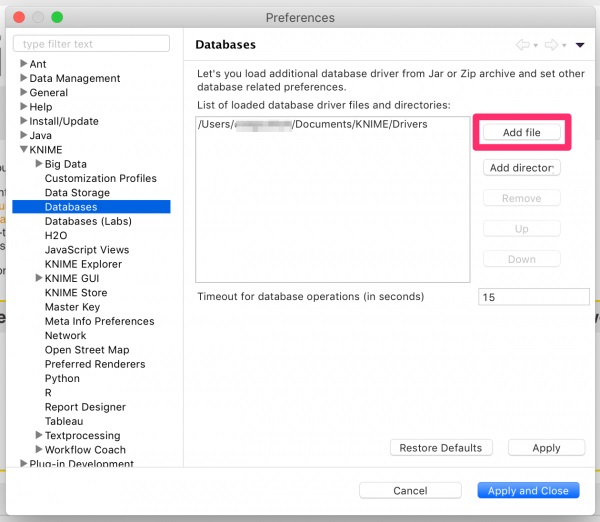
図3:KNIME[Preferences]の[Database]設定
4.[Apply and Close]をクリックし、「Database Connector」ノードをワークフローに追加して、JDBCドライバが正しくインストールされていることを確認します。
5.「Database Connector」ノードのConfigureを開き、[Database driver]項目のドロップダウンで新しくインストールした(net.snowflake.client.jdbc.SnowflakeDriver)を選択し設定します。
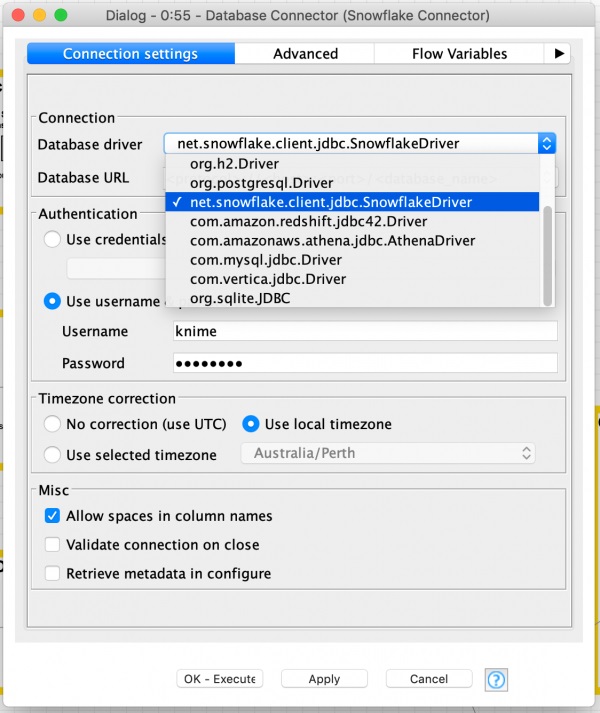
図4:「Database Connector」ノードのConfigure
次に「Snowflake」の[Database URL]を設定します。
jdbc:snowflake://<account_name>.<region_id>.snowflakecomputing.com/?<connection_params>
この接続文字列には、ウェアハウスまたはデータベースの名前を次のように追加できます。
jdbc:snowflake://myaccount.eastregion.snowflakecomputing.com/?warehouse=EXAMPLEWAREHOUSE&database=EXAMPLEDB&schema=public
接続URLに追加することをお勧めします。
CLIENT_SESSION_KEEP_ALIVE=true
たとえば、完全なJDBC接続文字列は次のようになります。
jdbc:snowflake://myaccount.eastregion.snowflakecomputing.com/?warehouse=EXAMPLEWAREHOUSE&database=EXAMPLEDB&schema=PUBLIC&CLIENT_SESSION_KEEP_ALIVE=true
最後にユーザー名とパスワードを入力し、[Apply]をクリック、ノードを実行し成功すると、緑色のインジケータライトが点灯します。
「Snowflake」およびデータベースの起動
「KNIME」の大きな利点の1つは、ETL/ELTまたはデータサイエンスのプロセスに合わせてクラウドのデータウェアハウスを動的に調整するワークフローを作成できることです。「Database SQL Executor」ノードを利用することで、データをアップロードして処理する前に「Snowflake」とデータベースを作成して起動するワークフローを作成できます。
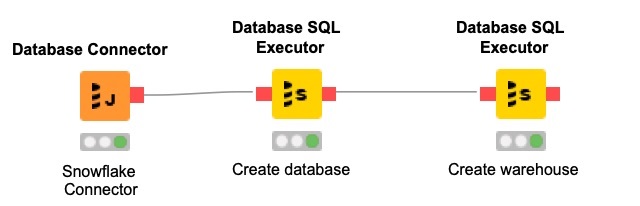
図5:KNIMEワークフロー
一連の「Database SQL Executor」ノードを使用することで、データベースとデータウェアハウスを作成できます。「KNIME」からデータベースに直接データを書き込めますが、大量のデータを読み込む場合は、一括データ読み込みを行うことをお勧めします。
Snowflakeでは、データベースに情報を取り込む前に、Snowflake内にデータベースとウェアハウスを作成する必要があります。
「Snowflake in20Minutes」 ガイドと同じ手順に従って、まず単純なクエリを使用してデータベースを作成します。
create or replace database knimedemo;
次のDatabase SQL Executorノードはウェアハウスを作成します。
create or replace warehouse knime_wh with
warehouse_size='X-SMALL'
auto_resume = true
initially_suspended=true;
「KNIME」で実行するとオブジェクトが作成され、テーブルとデータを動的に入力できるようになります。SQLでcreateコマンドまたはreplaceコマンドを使用すると、再実行してもエラーが既に存在する場合は発生しません。
「Snowflake」にデータをアップロード
データを準備する
営業チームからきたExcelの一万件の注文データがあります。
サンプルExcel「TableauのSample–APACSuperstore.xls」
「Tableau Desktop」をインストールするとローカルコンピュータの「My Tableau Repository\Datasources」フォルダにあります。
このデータには返品情報も含まれているため、売上と利益の正確な数値を取得するには、データから返品情報を除外する必要があります。
「Excel Reader(XLS)」ノードを使用してExcelファイルを読み込み、簡単な変換を実行しデータセットから[Customer ID]と[Product ID]を除外、文字列を日付と時刻に変換し、値を小数第二位に丸めます。
返品データはオンラインのeコマースプラットフォームのREST APIからJSON形式でインポートされます。このデータを「KNIME」に読み込み、それを表形式に変換してこのデータと注文データをブレンドして正確なデータセットを取得します。
データセットを結合する
「JSON Path」ノードを使用し[Order ID]列と[Returned」列を出力し、「Ungroup」ノードを使用してデータセットを従来の見た目のデータ・テーブルに戻し、Excelデータに結合します。半構造化データから構造化データへの変換です。
「Joiner」ノードで2つのデータセットを結合しましょう。
すべての注文に “Returned” の値があるわけではないので、「Join mode」で “Left Outer Join” を選択し、上部入力と下部入力を両方とも[Order ID]に設定する必要があります。
次に、「Row Filter」ノードを利用し、[Exclude rows by attribute]値を使用してReturned列をテストし、パターンマッチング「Yes」を使用してマッチングを行います。
「Snowflake」へのデータのアップロード
「KNIME」では入力データに基づいてテーブルを動的に作成されます。これにより、データセットが変更され新しい列が追加されたりするたびに、SQLコードを絶えず編集してテーブルを作成しなければならないという問題がありません。
以前に使用した「Database Connector」ノードがあれば、コピーして使用することができます。
データベース削除テーブルを追加し、「tableaudemo」テーブルを削除して、作成済みの既存のテーブルをすべて削除します。ワークフローの失敗を防ぐには、「Database Drop Table」ノードを構成し、「Fail if table does not exist」(テーブルが存在しない場合は失敗します)の選択を解除します。
このチュートリアルで使用しているテーブル名は次のとおりです。
tableaudemo
「Column Filter」ノードから入力を受け取り、「Database Writer」ノードで入力内容に基づいて動的にテーブルを作成します。
上記で使用したテーブル名を入力して、「SQL Types」タブが正しいことを確認してください。[Order Date]と[Ship Date]の各フィールドを “date” に設定し、「Advanced」タブの下の[Batch Size」の値を大きくしたいので “1,000” と設定しています。
[Batch Size]はバッチで一度に書き込むレコード数を制御します。この値を使用して、アップロード帯域幅に一致するサイズを設定できます。
これらのノードを実行すると、表が作成され、データがクラウドデータウェアハウスにアップロードされ、Tableauレポートを作成できるようになります。
「Database Reader」ノードを使用して、検証のためにこのデータを「KNIME」に戻すことができます。
私は技術部門には興味がないので、「Row Filter」ノードを使用し、「Tableau」にエクスポートする前に、家具と事務用品部門のみを抽出するようにデータをフィルターすることができます。
「KNIME」の最新バージョンには、Tableauファイルを.Hyper形式で書き込むためのノードが含まれています。
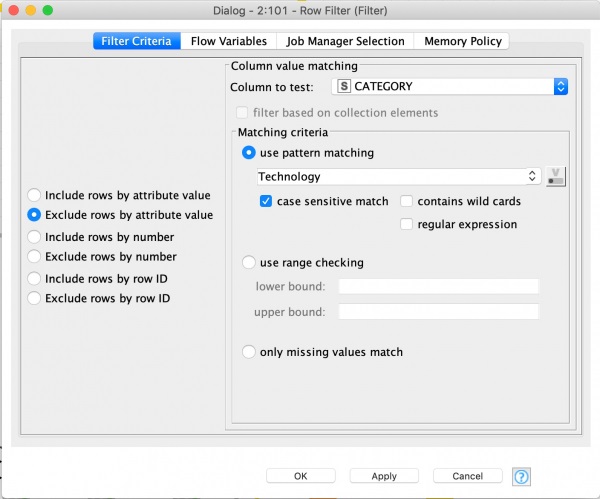
図6:「Row Filter」ノード。[CATEGORY]=”Technology”(技術部門)を除外します。
結果
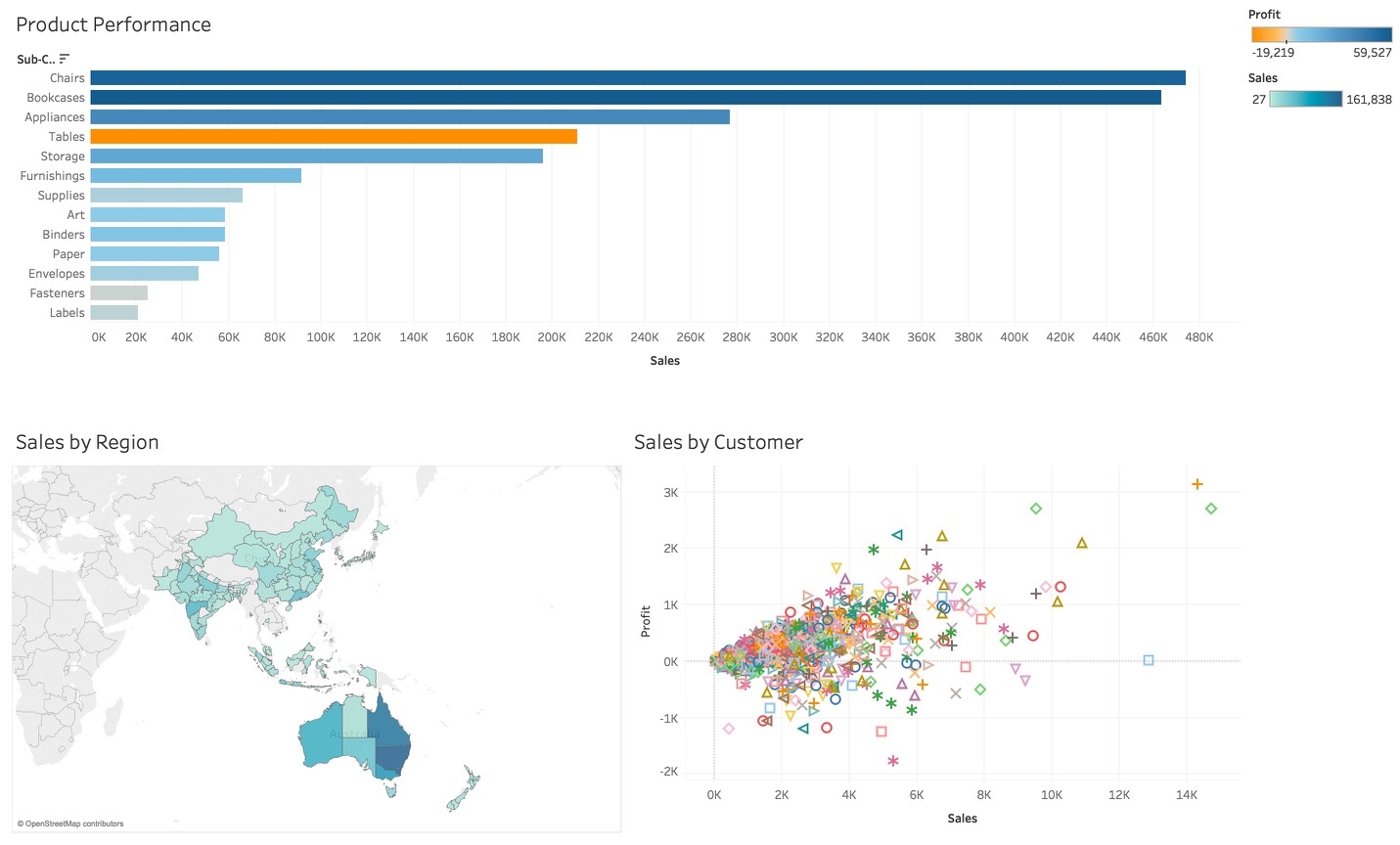
図7:「Tableau Desktop」でエクスポートされたデータが表示
利益率でバーの色をオレンジからブルーにスケーリングするように設定してみると、Tablesの売り上げはかなりありますが、実際には利益が少ないことがわかります。このマップは州ごとに売上高で色をスケーリングしており、倉庫、出荷、その他の物流に関しての決定支援に使えます。
例えば、オーストラリアの東海岸では売上が集中しているので新たに倉庫を建てる必要があるかもしれません。
散布図は利益と売上をプロットしています。この可視化により利益は売上に必ずしも比例していないことが読み取れ、最も価値のある顧客と最も価値の低い顧客を特定することができます。このダッシュボードを使用することで、現在の販売状況を示すだけでなく、背景等の情報が追加され、洞察力と意思決定能力を向上させることができます。
.Hyper形式ファイルには、プレゼンテーションに必要なデータ ([Product Performance]、[Sales by Region]、[Sales by Customer]) が含まれています。
「Tableau Desktop」を開き、エクスポートしたデータを直接開くことができます。.Hyper形式ファイルにはプレゼンテーション用に必要なデータだけが抽出されています。組織での要件が変わりデータの処理方法が変化した場合には、データセット、計算、予測モデリングなどを追加してKNIMEワークフローを拡張することができます。
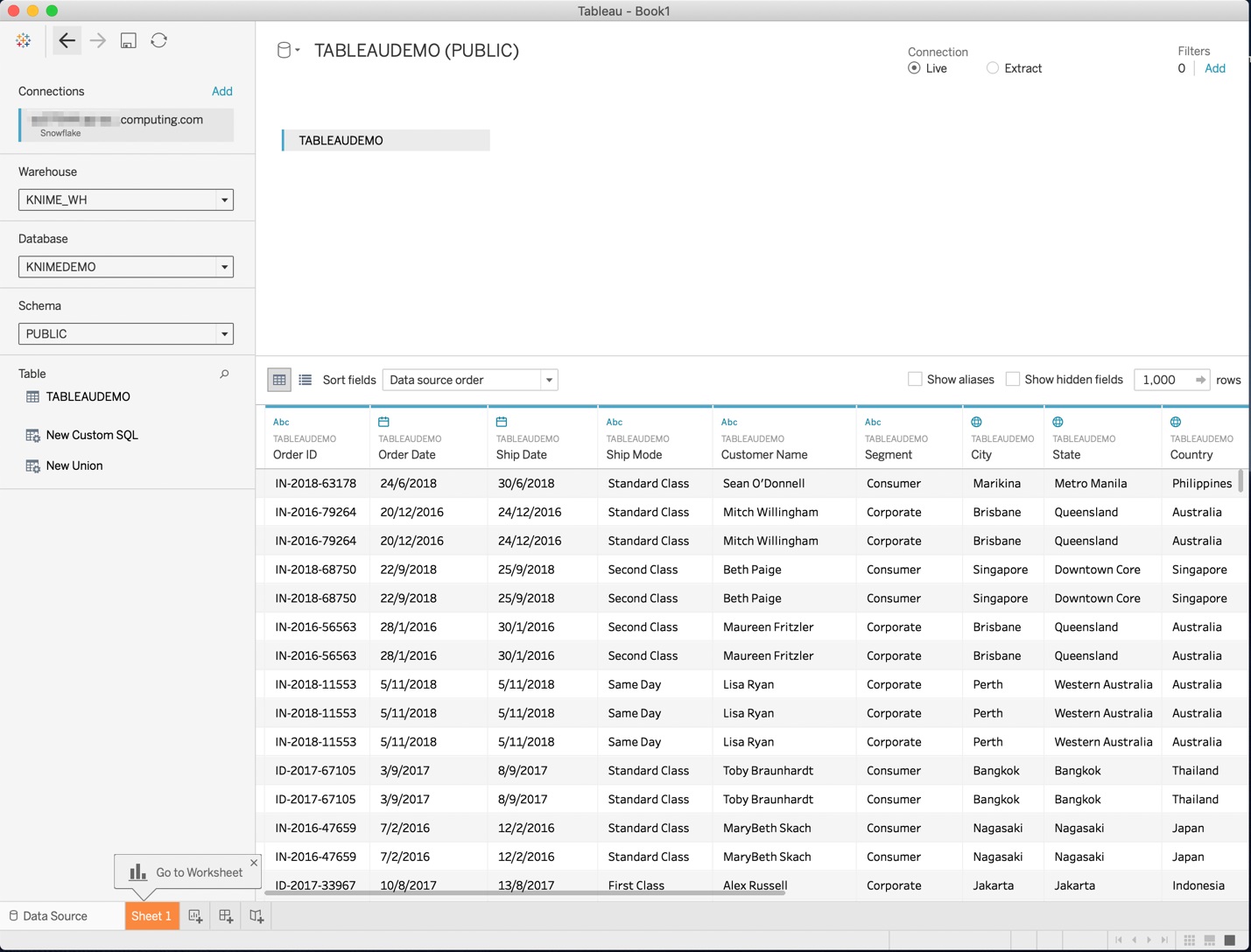
図8:「Tableau」に連携した売上データの抜粋
参考文献
このワークフローはKNIME Public Examples SERVERから入手できます。01_Data_Access / 02_Databases / 11_Snowflake_meets_Tableau
著者について
Craig Cullum
オーストラリアのパースに本拠を置くForest Grove Technologyの製品戦略および分析担当ディレクター。さまざまな業界や国で分析ソリューションを提供してきた12年以上の経験を持つ彼は、現在、データ愛好家の熱心なチームを率いて、今日のビジネス上の問題に対する革新的なソリューションを見つけています。Forest Grove Technologyは、KNIMEの信頼できるパートナーです。