

ブログ

最新情報をお届けします。

ガイド付き視覚化と探索
 経験豊富なデータサイエンティストでもビジネスアナリストでも、日常業務の1つは、直面している分析の種類に関係なく、データから関連情報を簡単かつスムーズに抽出することです。
経験豊富なデータサイエンティストでもビジネスアナリストでも、日常業務の1つは、直面している分析の種類に関係なく、データから関連情報を簡単かつスムーズに抽出することです。
これには、データの視覚化を使用することが一番効果的です。チャートとグラフを使用して、データの複雑さを視覚的に要約します。 データの視覚化に必要な専門知識は、主に次の2つの領域に分けることができます。
①データセット列のサブセットを正しく準備および選択し、それらを適切なチャートで視覚化する機能
②視覚的な結果を解釈し、表示内容に基づいて適切なビジネス上の意思決定を行う機能
この記事では、BIの視覚的インターフェース、つまり「ガイド付き分析」がその場で視覚化し、それらの視覚化を通じて複雑なパターンを特定する方法を説明します。
「ガイド付き視覚化」とは、ビジネスアナリストを生データからグラフに導くことです。ビジネスアナリストはプロセス全体を案内され、視覚化する列を選択するよう求められますが、他のすべては自動化されます。対照的に、「ガイド付き探査」はデータサイエンティストを大量のデータから、統計的に興味深いパターンを示す自動的に計算された視覚化セットにナビゲートします。
この記事の最後のセクションでは、コンポーネントの共有による機能の再利用など、これらのガイド付き分析アプリケーションの構築に使用される一般的なプラクティスと戦略を要約します。
目次
データ選択から適切なグラフ作成を行うためには?
データの視覚化の課題
多くの場合、データには分析に適さないデータ型の値が含まれています。
たとえば、日付値が文字列として保存されている場合、2つのイベント間の日数をどのように計算しますか?また、数字の「6」と「7」は、金曜日と土曜日を示す場合、文字列としてより意味がありますよね?
これらの種類のデータ品質の問題はデータを分析するだけでなく、レポート用のグラフの選択にも影響します。たとえば、時間別に値をプロットしたり、曜日に色を割り当てたい場合、これらの列には適切なデータ型が必要です。
ただ、完全なデータであってもデータがどのように展開したかを示したり、データ内の関係を強調したりする、最適な視覚化が常に得られるとは限りません。正しいグラフは目的によって異なります。1つ以上の特徴を視覚化しますか?それはカテゴリ型ですか、数値型ですか?ここでは、ビジネスアナリストとしての専門知識に基づいて、意思を最もよく伝えられるグラフを選択します。
昨今、グラフの種類や視覚化のためのツールが増えているため、最適なグラフを選択する作業は簡単ではありません。さらには、グラフの作成を簡単に行うほど、プロセスに介入するのが難しくなります。ビジネスアナリストが介入して追加できるようにした専門知識を、自動化されたデータサイエンスタスクと組み合わせるのが理想的です。つまり、提供された専門知識に基づいて視覚化を自動的に作成します。
ガイド付き視覚化:可能なかぎり自動化し、必要な場合は対話しながら手動で設定
多くのオールインワン視覚化ソリューションの欠点は、生データへのアクセスからカスタマイズされたグラフのダウンロードまで、データ視覚化のプロセス全体が考慮されていないことです。このようなツールを使用すると、不明瞭なデータを提供したにもかかわらずグラフを生成できてしまいます。
また、データのサブセットのみを視覚化する場合は、最初に入力データをフィルター処理する必要があります。最初に入力データをフィルター処理せずに、データが1年全体の売上で構成されている場合、昨年の売上の推移を示すグラフのみを選択できます。この場合、第4四半期の売上開発のみに関心がある場合はそれほど便利ではありません。
ガイド付き視覚化は、図1に示すように、グラフを構築するプロセスのより包括的なビューを提供します。
図1:生データへのアクセスからカスタマイズされたグラフのダウンロードと展開までのデータ視覚化のプロセス
データクリーニングフェーズでは、優秀なビジネスアナリストでさえ、定数値のみを含む列または明確な値がほとんどない数値列を簡単に見落とす可能性があります。日付と時刻の値を見つけるのは簡単ですが、データ型を変換するときに情報が失われたり変更されたりしないようにする必要があります。
このような課題を考えると、これらのタスクをできる限り自動化したいのですが、結果を盲目的に信頼したくありません。 ガイド付き視覚化のプロセスでは、ビジネスアナリストは各プロセスステップの後に結果を確認し、必要に応じてさらに変更を適用できます。
データを準備、列選択を完了するとグラフの最初のバージョンの作成に進みます。
折れ線グラフや棒グラフなどを好むかどうか尋ねられた場合、これらのオプションを頭の中で構築して決定を下すことはできませんでした。
ガイド付き視覚化プロセスでは、関連する可能性のあるグラフのコレクションを表示するダッシュボードを使用して、関連するグラフの選択が簡単になります。
この時点で、ビジネスアナリストの専門知識がプロセスに戻されます。
どのグラフが私の目的に最も適していますか? タイトルとラベルは参考になりますか?
グラフの範囲は適切ですか? これらの変更は、インタラクティブダッシュボードから適用できます。
準備ができたら、最後のステップはグラフを画像ファイルとしてダウンロードすることです。
ガイド付きデータの視覚化のワークフロー
上記のガイド付き視覚化プロセスには、データクリーニングから視覚化する列の選択、一連の関連グラフへのアクセス、グラフの選択とカスタマイズ、最終グラフの画像ファイルとしてのダウンロードまでのプロセスステップを自動化するロジックが必要です。
それでは、ガイド付き視覚化ワークフロー自体と、関連する手順を見てみましょう。
図2にこれらの手順を示します。各コンポーネントはプロセス中にユーザーとの対話を可能にしますが、コンポーネント間の計算はバックグラウンドで完全に自動的に行われます。 KNIME Hub からワークフローをダウンロードできます。
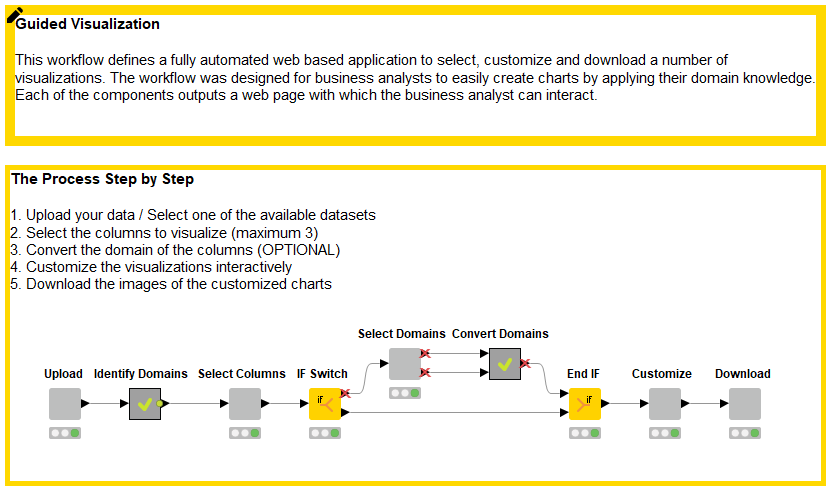
図2:ガイド付き視覚化のワークフロー
各コンポーネントは相互に作用します。「Upload」 -> 「Select Columns」 -> 「Select Domains」 -> 「Customize」 -> 「Download」
- 最初の対話コンポーネント「Upload」で使用するデータファイルを選択します。
- 2番目の対話コンポーネント「Select Columns」で視覚化する列を選択します。
- 3番目の対話ポイント「Select Domains」コンポーネントはオプションです。選択した列のデータ型を手動で変更できます。
- 4番目の対話ポイントは、「Customize」コンポーネントです。 列の数とそのデータ型に基づいて、関連するグラフのコレクションが表示されます。最低一つのグラフを選択し、ラベルを変更、それらをズームし他の視覚的な変更を適用できます。
- 最後の5番目の対話ポイントは、選択およびカスタマイズされたグラフを画像としてダウンロードできる「Download」コンポーネントです。
ビジネスアナリストの特定の要求のすべてが、上記のガイド付き視覚化の手順と一致するとは限りませんが、同じプロセスの拡張バージョンと変更バージョンでは、同じロジックが引き続き有用です。
たとえば、ワークフローにコンポーネントとしてより多くのインタラクションポイントを簡単に挿入できます(図2)。
また、これまでのプロセスで提供されているよりも多くのグラフを提供することもできます(図3)。
これを行うには、図4に示すネストされたコンポーネント内に新しいノードを追加します。
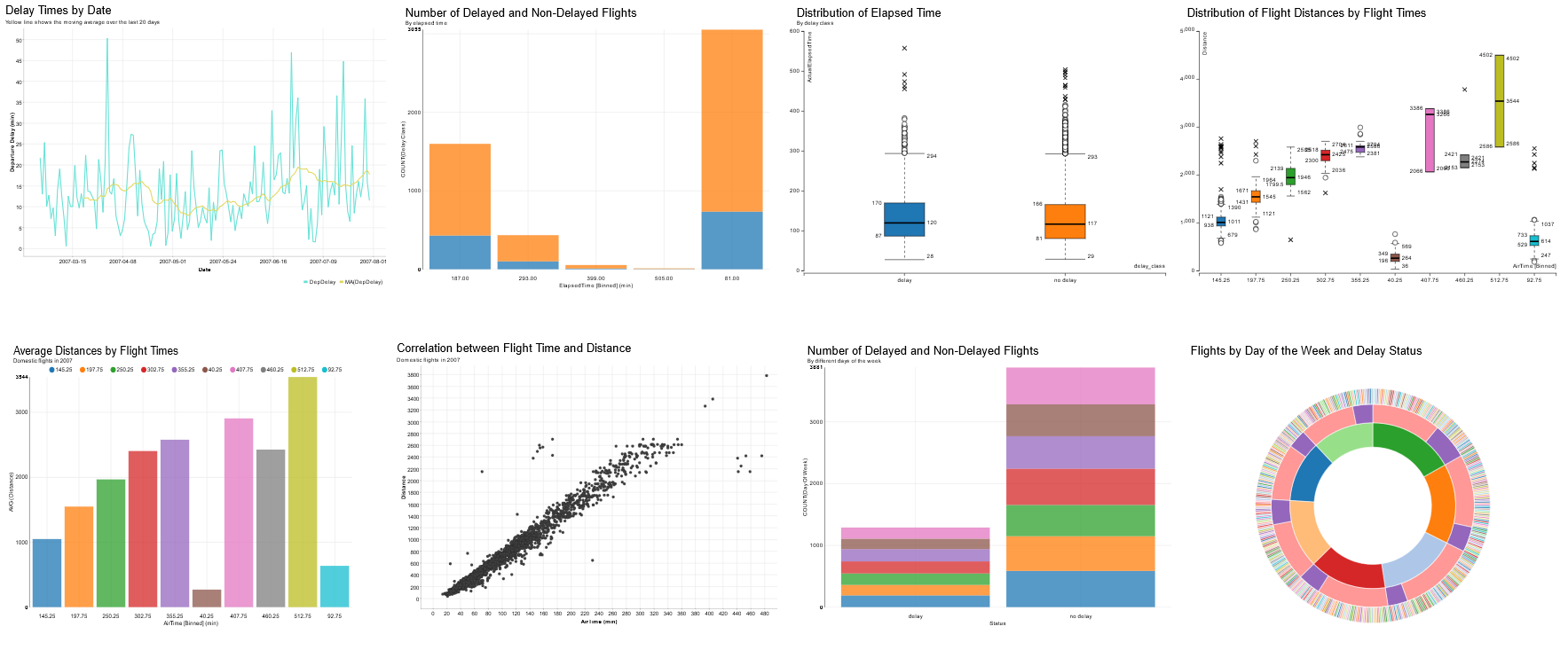
図3:二つの列を選択したときに、ガイド付き視覚化プロセスによって生成される可能性のあるグラフの一部。
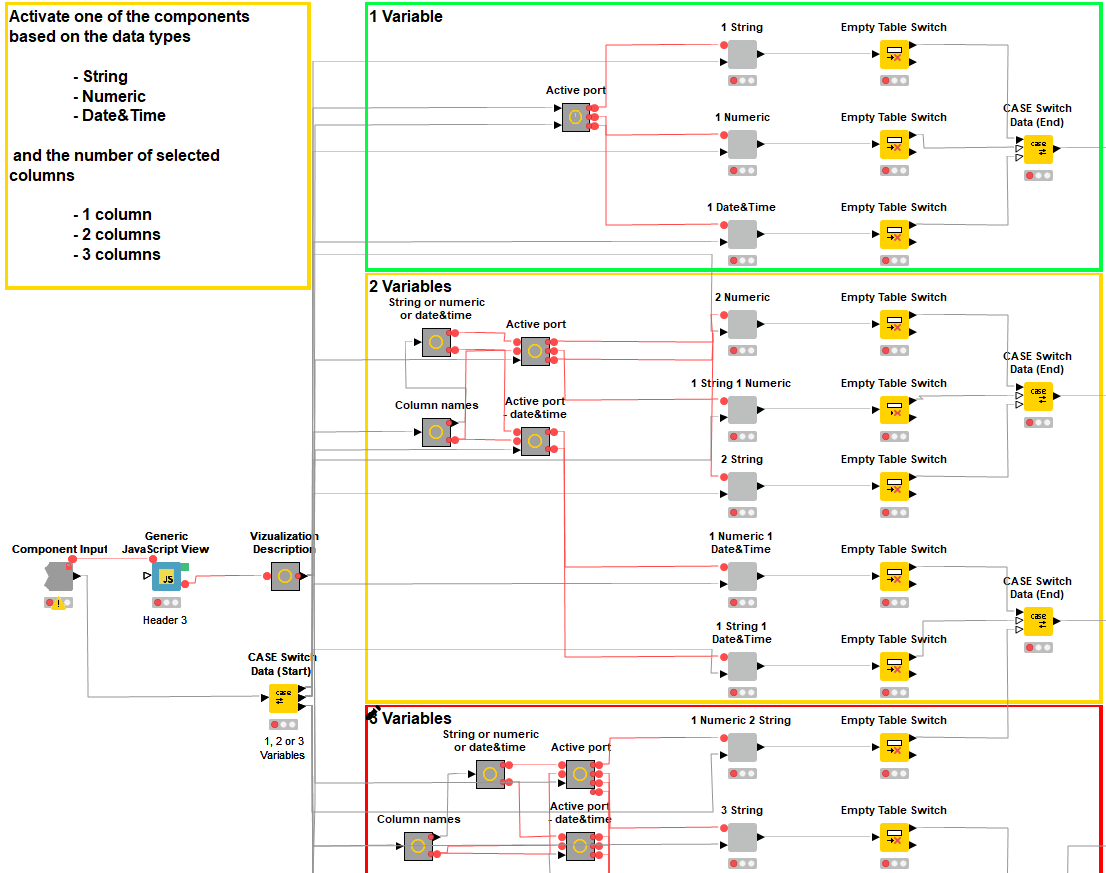
図4:「Customize」コンポーネントのワークフロー
未開拓のデータから興味深いデータを導く
データサイエンティストなどの経験豊富なユーザーも、データが未開拓で複雑なデータセット(暗号化された名前を持つ列など)を含むものである場合、視覚化するプロセスに困難を感じるかもしれません。
この問題は、分析プロセスの最も初期の段階では一般的であり、専門家は仮説を設定する前にデータを理解する必要があります。
データの視覚化は、データ探索のための強力なツールですが、何百もの未知の列がある場合、まず何を視覚化する必要がありますか?
列間の興味深いパターンを自動的に視覚化する
視覚化するのに最適な列をすばやく見つけるアプローチは、統計的検定を使用することです。ここでは非常に大きなデータセットを用い、適切なサンプルを取得し、単一の列、列のペア、さらには列のグループの統計情報の計算を開始します。通常、計算コストが高いため、取得するサンプルが大きすぎないことを確認する必要があります。
このアプローチを使用すると、興味深いパターンを見つけることができます。たとえば、最も相関の高い列のペア(図6)、歪んだ分布を持つ列、または異常値の多い列です。
統計テストでは、当然データのドメインが考慮されます。たとえば、カテゴリ列と数値列の間の興味深い関係を見つけたい場合、相関尺度を使用せず、代わりに「分散分析」(図7)を使用します。
最終的に、パターンの長いリストと視覚化する関係が見えてきますので、視覚化する内容に基づいて、興味深いパターンごとに最適な視覚化を見つけることができます。
最も相関の高い列を視覚化するにはどうすればよいですか? 散布図を使用できます。
列に外れ値を表示するにはどうすればよいですか?ボックスプロットを使用できます。 興味深いパターンごとに最適な視覚化を見つけることは重要なステップであり、視覚化の背景が必要になる場合があります。
でも、最初にパターンを自動的に検出し、次にそれらを最適なチャートで視覚化できるツールがあればどうでしょうか?私たちはデータを用意するだけです。
ガイド付き探索ワークフロー
これが、「ガイド付き探索」のKNIMEワークフローサンプルです。(図5)データを読み取り、統計を計算し、ダッシュボード(図6)を作成し視覚化します。KNIME Hub.よりダウンロードできます。
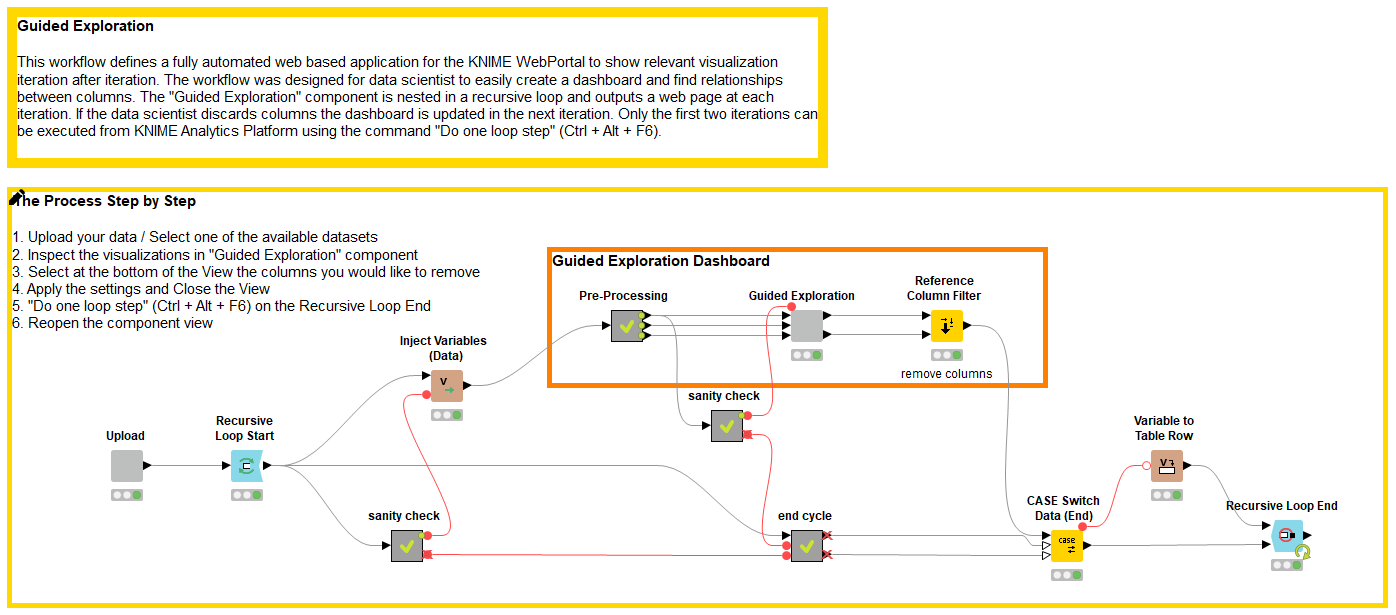
図5:ダッシュボードで自動的に視覚化するガイド付き探索のワークフロー
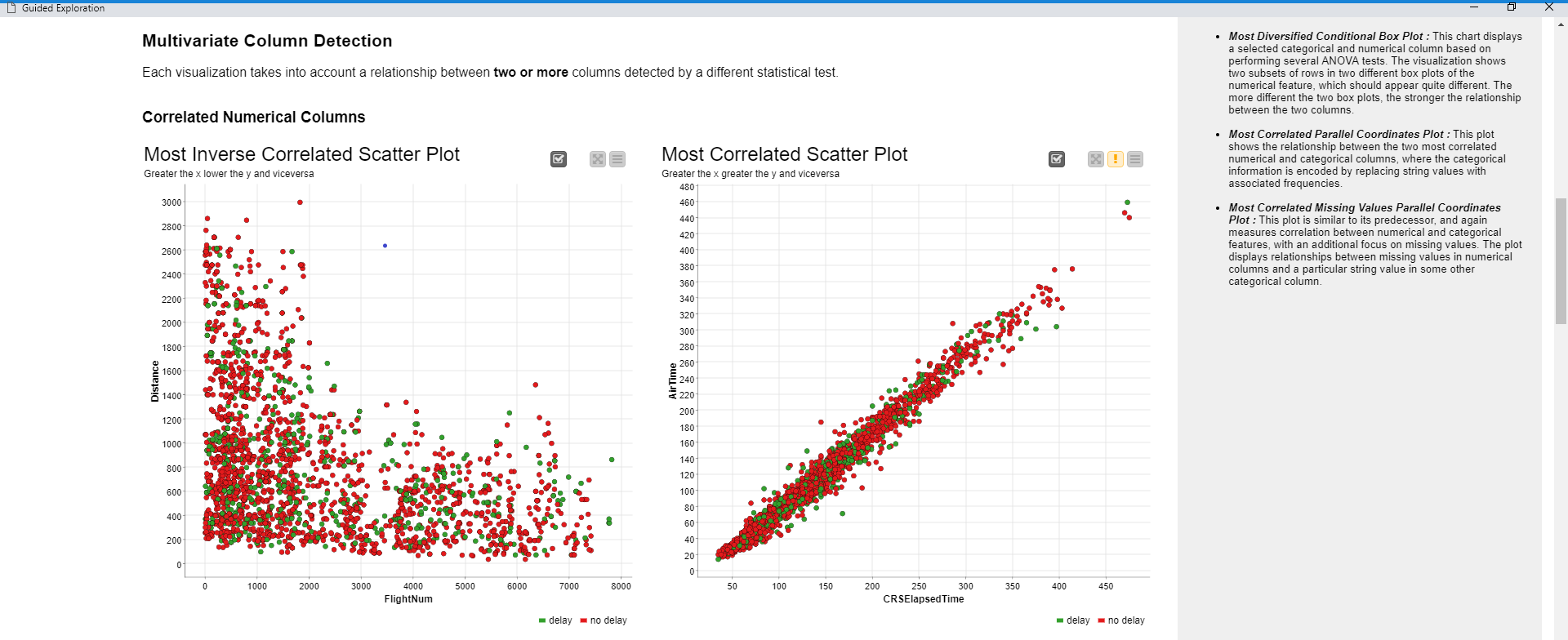
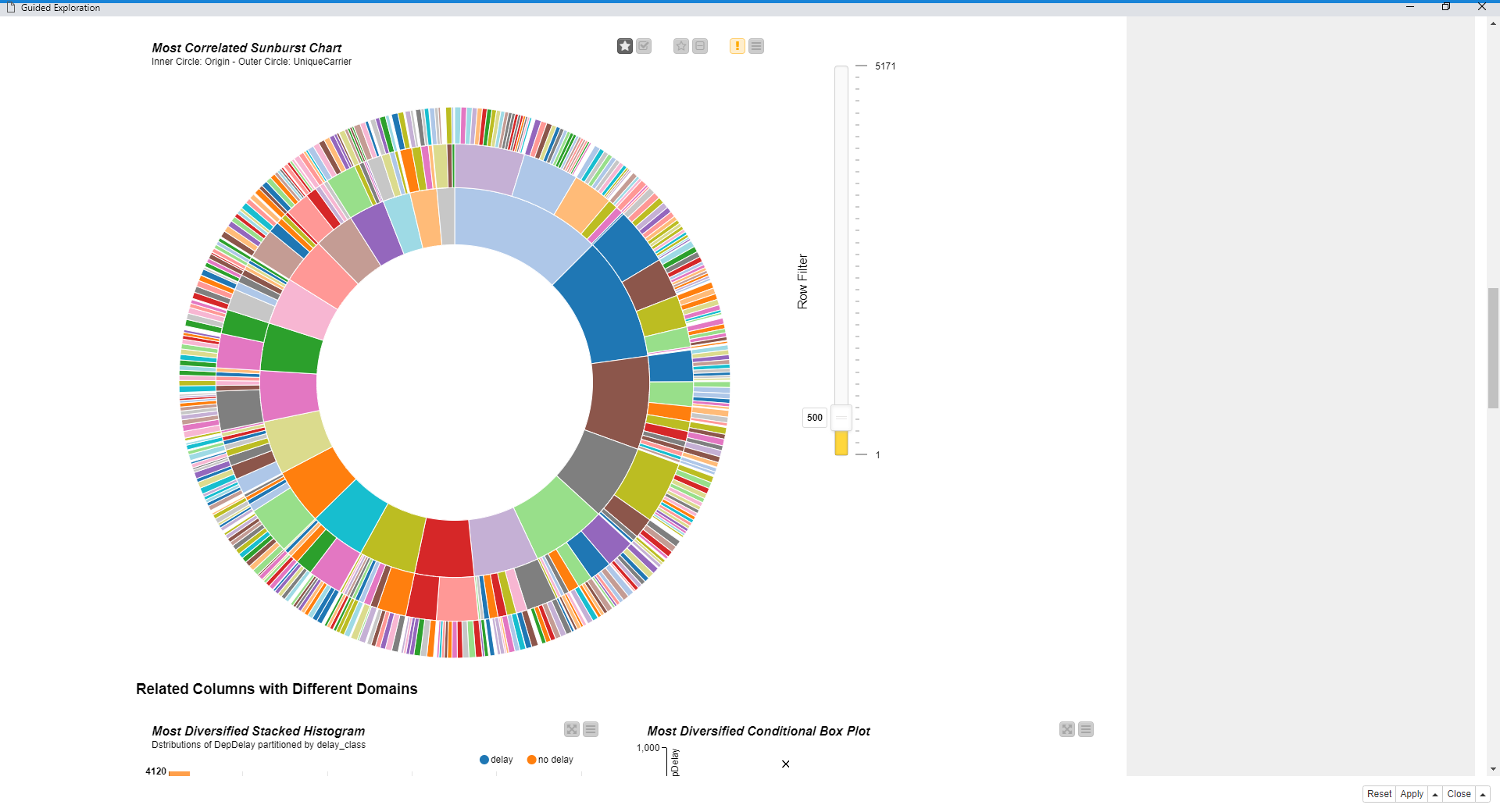
図6:ガイド付き探索ワークフローによって生成されたダッシュボードの一部
人間参加型(ヒューマンインザループ)の機械学習
生データでは、最も激しいパターンは実際には品質の悪い列の結果です。実質的に同一の2つの列は、その後、高い相関をもたらします。 または、定数または欠損値が多すぎる列など。
さらに、たとえば、同じものを異なる単位で測定するため、明らかな関係を持つ列があるかもしれません。
これらのパターンの例を図6および7に示します。原因が何であれ、生データで計算された統計を初めて視覚化するとき、結果は残念なほど退屈になるでしょう。
そのため、図5のワークフローに示すように、ダッシュボードが「Recursive Loop」(再帰ループ)になっています。これが機能する方法は、何らかの理由で興味のない列を繰り返し削除できることです。
そこで、人間が参加し、手を加える必要が出てきます。具体的には、ダッシュボードに表示される内容に基づいて、保持するデータ列と保持しないデータ列を繰り返し選択します。数回の反復の後、かなりの数の興味深いチャートが表示されます。
ここで必要なことは、座ってリラックスし、ワークフローで単変量および多変量解析を行い、重要な情報を抽出することだけです。
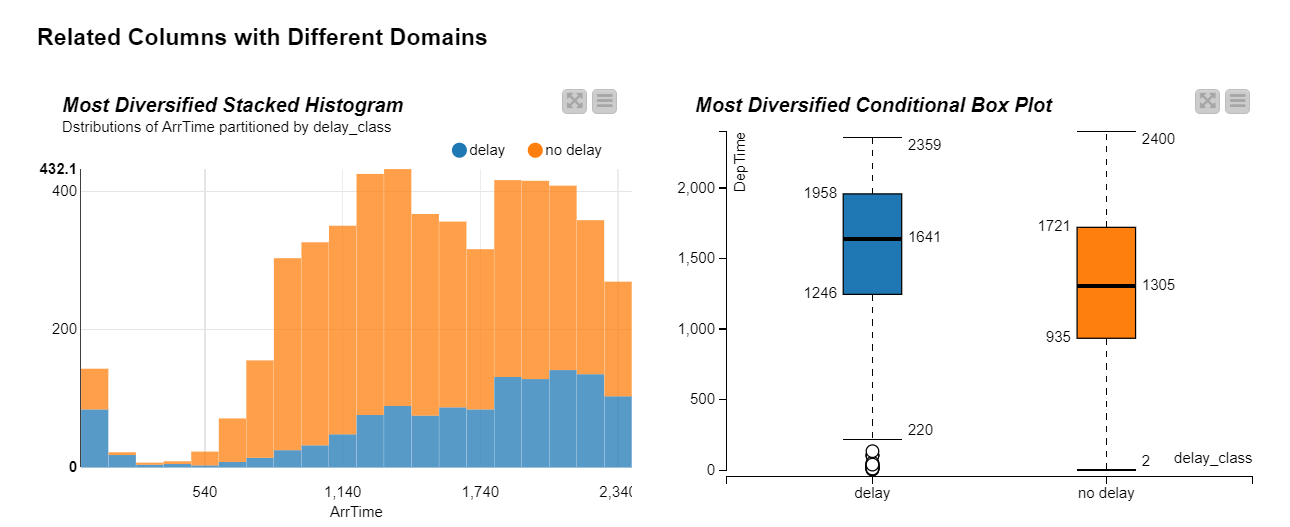
図7:積み上げヒストグラムと条件付きボックスプロット
データの2つのサブセットが異なる分布をどのように想定しているかを確認できます。 2つのカテゴリ値「遅延」と「遅延なし」を使用してデータを分割した場合、ANOVA(分散分析)テストを使用してこれを確認できます。
KNIMEでの実行方法
ワークフローを「KNIME Hub」からダウンロードし、「KNIME Server」に展開して「KNIME WebPortal」から実行し、反復後の反復-Webブラウザーから列を破棄できます。
ループの最後で、残っているいくつかの関連する列で何をするかはあなた次第です。
結果を単純に出力するか、ワークフローにノードを追加して、すぐに他の手法で分析を拡張できます。
たとえば、このプロセスのおかげで、今見つけたターゲットとの幸運な相関関係を考慮して、単純な回帰モデルをトレーニングできます。
あなたが何を思いついたのか、ぜひあなたのソリューションを「KNIME Hub」で共有してください!
カスタマイズ可能で再利用可能なプロセスステップ
上記の2つのワークフロー(および「KNIME Hub」で利用可能なガイド付き自動化ワークフロー)をよく見ると、それらの間にかなりの類似点があることがわかります。
レイアウト、内部ドキュメント、全体的なスタイル、機能などは、これらのワークフロー全体で一貫しています。
これは仕様によるものであり、この一貫性をワークフローに組み込むこともできます。KNIMEが提供するいくつかの機能を利用するだけです。
レイアウトとページデザイン
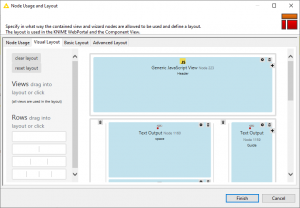
「KNIME WebPortal」の準備で新しく更新されたレイアウトパネルを使用することで、パディング、タイトル、ヘッダー、フッター、サイドバーなど、一貫してフォーマットされたページを作成できます。
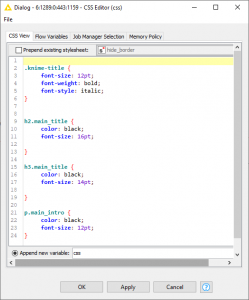
最初のCSSエディターノードと組み合わせると、フォントの選択、サイズ、配置などのプレゼンテーション要素を1つのコンポーネントに定義し、それらを後続のすべてのノードに渡して一貫した表示を実現します。
 カスタムHTMLを開発して、動的ヘッダーを作成することもできます。このHTMLをフロー変数として渡して、視覚化の横に表示される状況依存ヘルプテキストなど、追加の説明コンテンツを追加することもできます。
カスタムHTMLを開発して、動的ヘッダーを作成することもできます。このHTMLをフロー変数として渡して、視覚化の横に表示される状況依存ヘルプテキストなど、追加の説明コンテンツを追加することもできます。
上記は、ガイド付き視覚化およびガイド付き探索ワークフローで使用されたレイアウトおよび、ページデザインのすべての要素です。
Webページに対応するコンポーネントのビューを配置し、CSSスタイリングの表示と一貫性を強化し、動的ヘッダーとサイドバーを使用して「KNIME WebPortal」の外観をカスタマイズします。
コンポーネントの再利用と共有
ワークフロー間のルックアンドフィールの単なる類似性を超えて、それが理にかなっているワークフロー間で機能を再利用しました。
既存のワークフローで既に実装およびテスト済みのワークフロー機能をゼロから作成するのはなぜですか? わざわざまた一から作る必要はありませんよね?
これらのワークフローに実装する必要がある一般的なタスク(例えば、ファイルのアップロード、列の選択、画像の保存など)のために、コンポーネントを構築しました。
KNIMEを使用すると、ローカルリポジトリまたは「KNIME Hub」の個人のプライベート/パブリックスペースにコンポーネントを簡単に保存できるため、再利用が簡単になり、時間を大幅に節約できます。
また、新しい「KNIME Hub」を使用すると、コンポーネントとノードを独自のワークフローに直接インポートすることもできます!とても便利なので、ぜひ試してみてください!
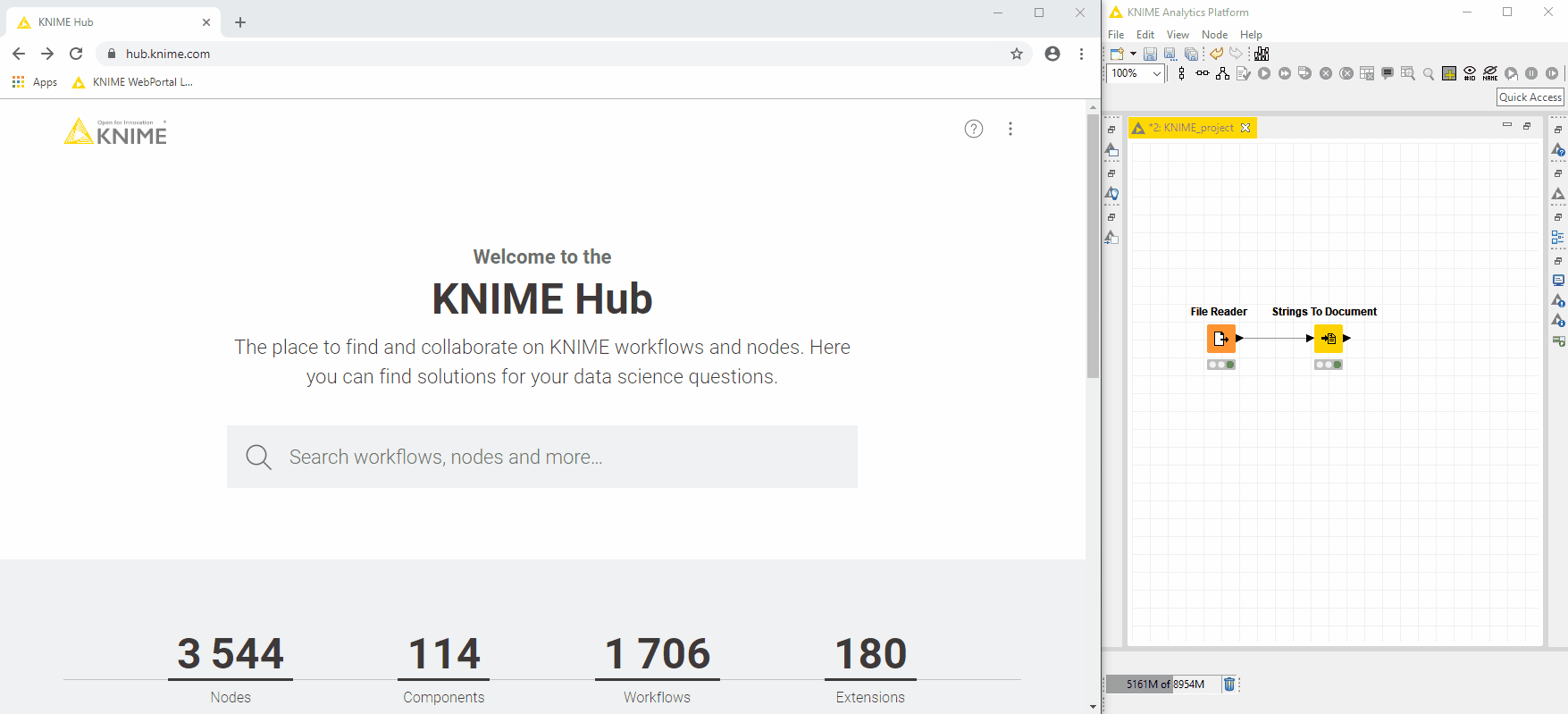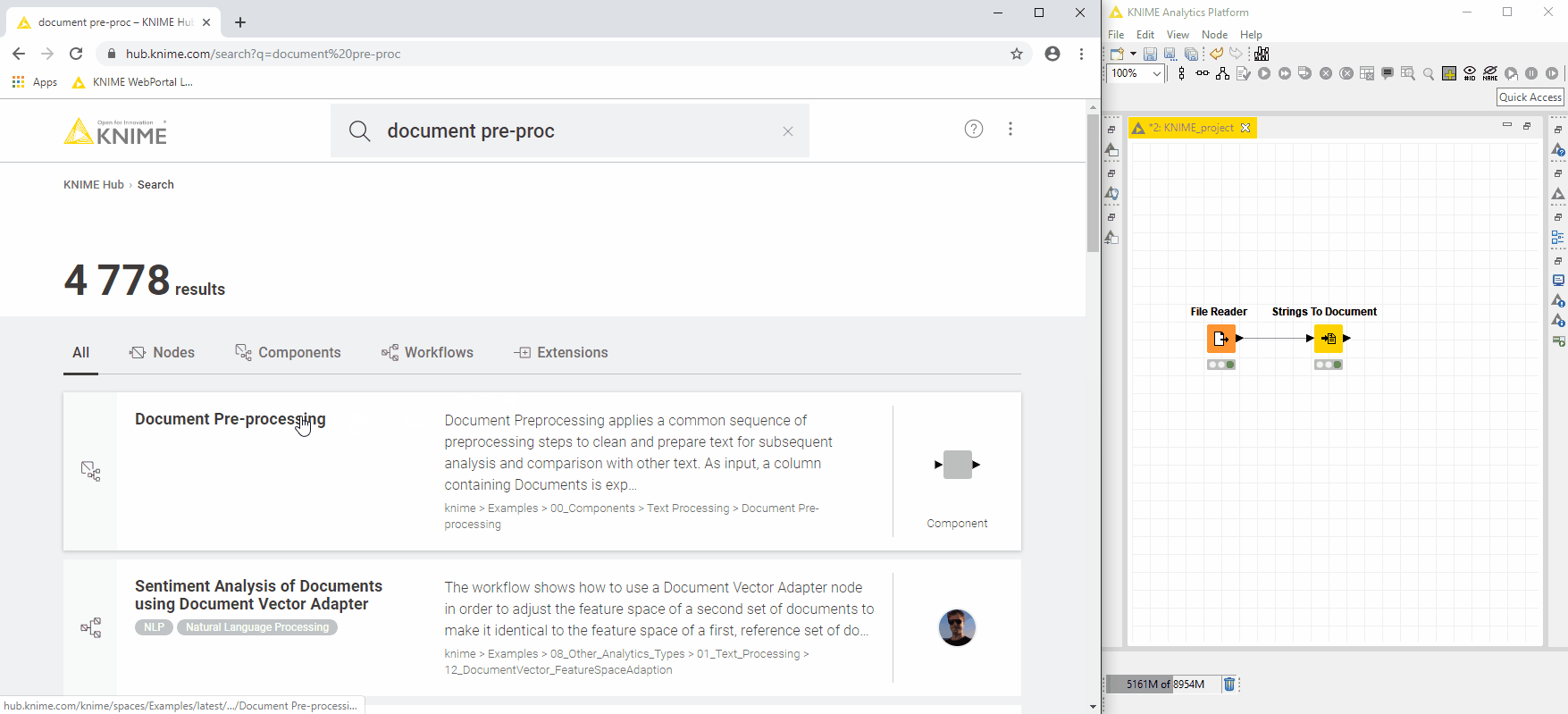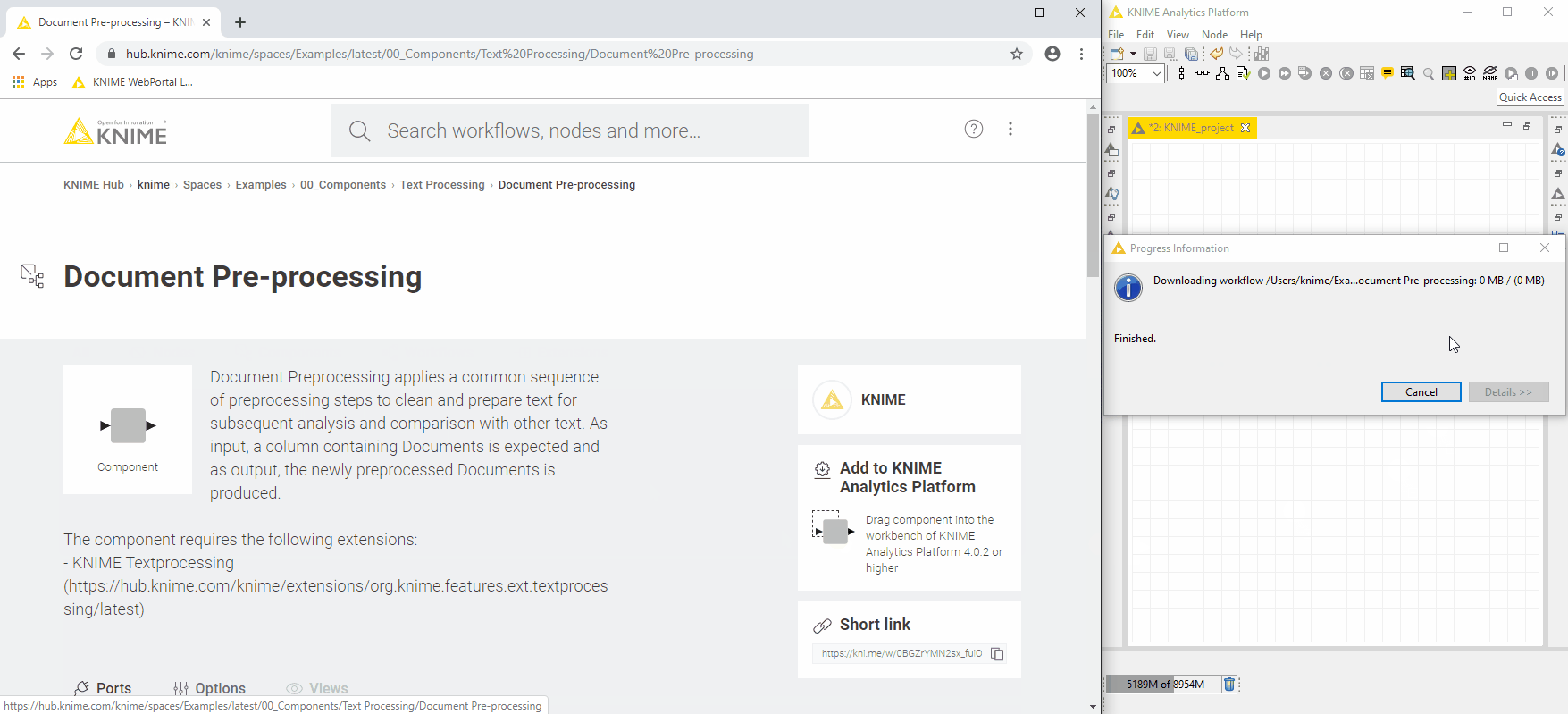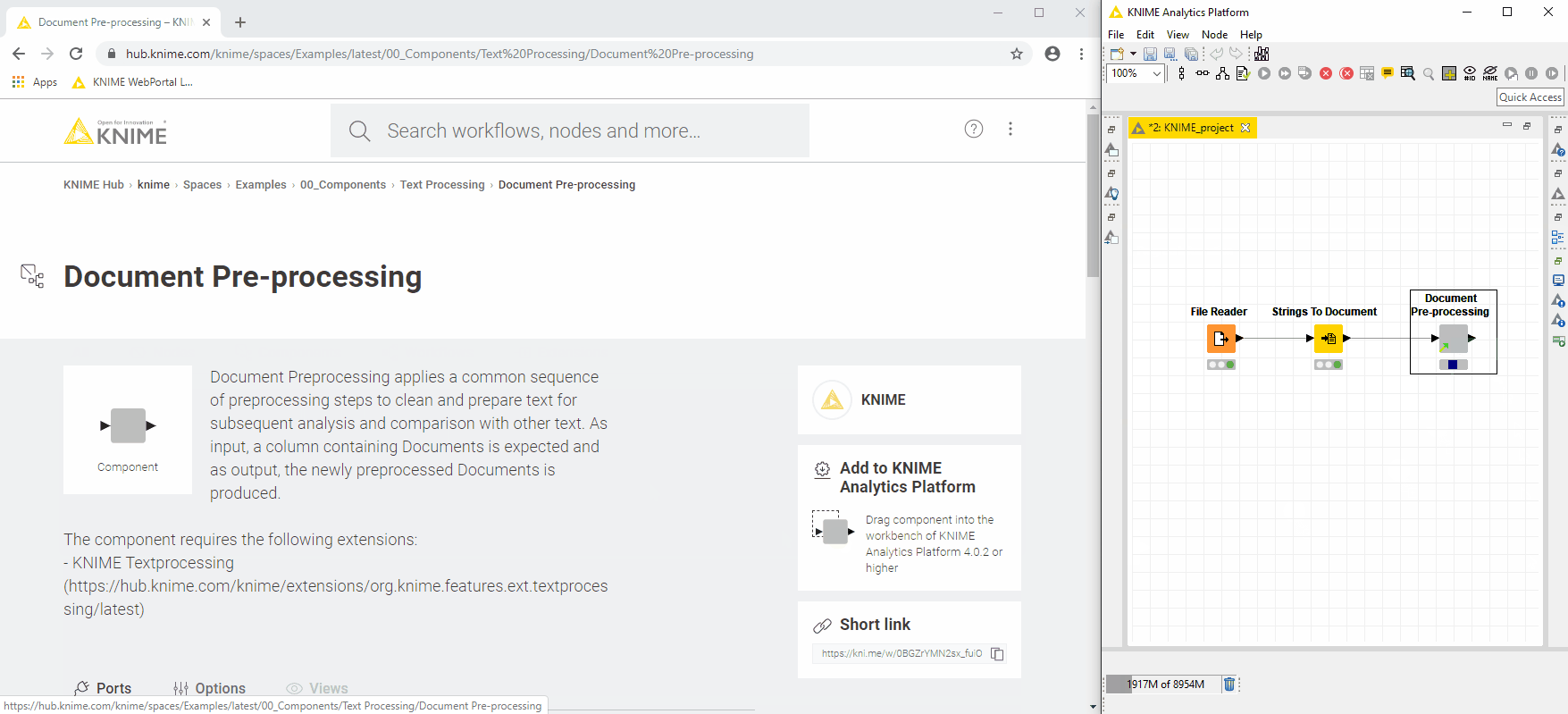
図8:共有コンポーネントを「KNIME Hub」からワークフローエディターにドラッグアンドドロップして再利用する
コンポーネントとメタノード
これらのワークフローの一貫性のもう1つの領域は、メタノードではなく、コンポーネントの使用方法でした。
「KNIME Webportal」でのユーザーインタラクションポイントが必要になるとわかっているときはいつでも、コンポーネントを使用するという意識的な決定を早い段階で行いました。
そのため、たとえば、モデルの列を選択したり、データを視覚化するために特定のグラフを選択したりするようにユーザーに求められたときは常に、このオプションは常にコンポーネント形式に含まれていました。
ガイド付き視覚化および、ガイド付き探索ワークフローで頻繁に繰り返されるタスクをカプセル化し、それらが生成するビューでユーザーとの対話を可能にする例は次の通りです。
図9:共有コンポーネントの例
論理的な操作、自動化された機能、または単純な組織化とクリーンアップが必要な場所で、メタノードが導入されました。必要に応じて、相互にメタノードをネストします(時には複数回)。
このプロセスでは、ワークフローの外観をきれいにし、理解しやすくすることが重要です。
ワークフロー設計の考慮事項
独自のワークフローを設計している場合、最初からコンポーネントとメタノードを使用するこの方法を検討することもできます。個々のノードをワークフローにドラッグアンドドロップする前に、まず全体的な機能を表す空のコンポーネントとメタノードから始めます。
具体的には、次のようになります。
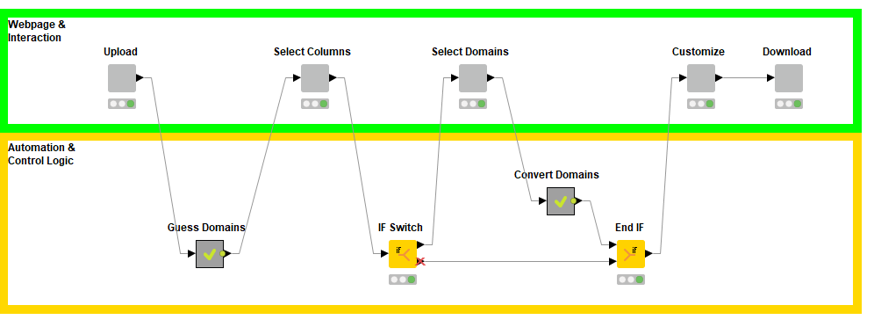
図10:ガイド付き視覚化のワークフローのプロセスステップ
上のボックス内の各コンポーネントは相互作用点に対応し、下のボックス内の各メタノードは自動化されたプロセスステップに対応します。
インタラクションポイントが何であるかを最初に検討し、必要なロジックと自動化のタイプを検討することで、最終的なワークフローがどのようなものになるかについての全体的なロードマップを作成します。その後、戻って必要な機能を備えたコンポーネントとメタノードに「入力」できます。
この方法で設計する利点は、再利用可能なコンポーネントを最初から組み込んでいるため、将来のワークフロー開発を大幅にスピードアップできることです。ワークフロー設計で考慮すべきもう1つのことは、ユーザーの操作と自動化のトレードオフです。
ユーザーは、ワークフローを実行するときにしばしば驚くべきことを行いますが、ユーザーが行う選択のいくつかは、まったく予期しないものになる場合があります。より多くのユーザーインタラクションを提供するほど、未知の動作が発生する可能性が高くなります。そのような動作を予測するには、追加の制御ロジックを開発する必要があります。
一方、インタラクションポイントが少ないと、それほど複雑ではない複雑なワークフローになります。スイートスポットの場所を決める必要がありますが、実際には、絶対に必要な相互作用のみに焦点を当てることが良いアプローチであることがわかりました。
最小限の操作で、非常に優れたWebポータルアプリケーションを構築できるのです。
まとめ
ガイド付き視覚化と探索のプロセスには、多くの決定が必要です。
あなたが最も重要とすべき列は何ですか?
それらを視覚化するにはどうすればよいですか?
データを保持するためにすべての列が必要ですか?
適切なデータ型がありますか?
ビジネスアナリストは、グラフで示される開発を簡単に説明できますが、開発を視覚化するさまざまな方法を比較することは、自分の興味や専門知識の範囲外である場合があります。
一方、派手なグラフを作成する専門家は、必ずしもそれらを解釈するための最良の理解を持っているわけではありません。
そのため、領域外の専門知識を必要とする手順を自動化するアプリケーションは、日常のタスクを完了するのに実用的です。ここでは、ビジネスアナリストが生データから始めて、関連する有用な視覚化を生成する方法を示しました。
さらに、データサイエンティストが複雑なデータをよりよく理解できるようにするためのワークフローを紹介しました。