

読み込むデータを準備します。ここでは定番の「フィッシャーのあやめ」データを使います。https://archive.ics.uci.edu/dataset/53/iris/ (外部サイト)の「DOWNLOAD」をクリックし、ファイルをダウンロードします。ダウンロードしたファイル内のファイル名:iris.data は “,” 区切りのCSVフォーマットです。
導入ガイド
個人でのデータ分析に最適な「KNIME Analytics Platform(デスクトップ版)」の導入方法をご案内いたします。
組織での共有・自動化をご検討の方は KNIME Business Hub(サーバー版) をご覧ください。
活用リソース・最新情報
※KNIME社(英語)のサイトへ移動します

- ダウンロードする
- インストールする
- ワークフローを作成する
- エクステンションの追加
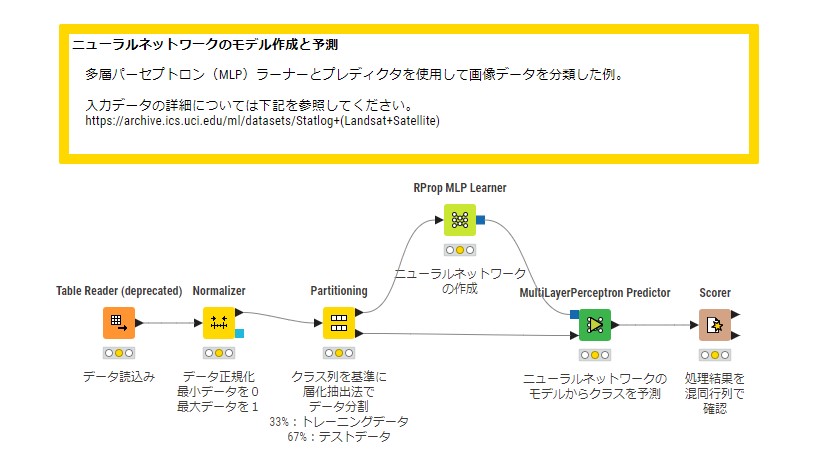
KNIME Community Hubへ日本語の説明を付与したサンプルワークフローを掲載しております。下記より無料でダウンロードいただけますので、ぜひお試しください。
※KNIME Community Hubの画面からKNIME Analytics Platformへ
専用アイコン![]() をドラッグ&ドロップすることで、インポートすることができます。
をドラッグ&ドロップすることで、インポートすることができます。
ドロップ先は、KNIME Explorer内の「LOCAL(Local Workspace)」もしくは、
その他任意の場所を指定してください。
※ダウンロードにはKNIME Community Hubへのログインが必要です。
1. データの準備
2. プロジェクトの作成
-
画面右上の「Create new workflow」をクリックします。
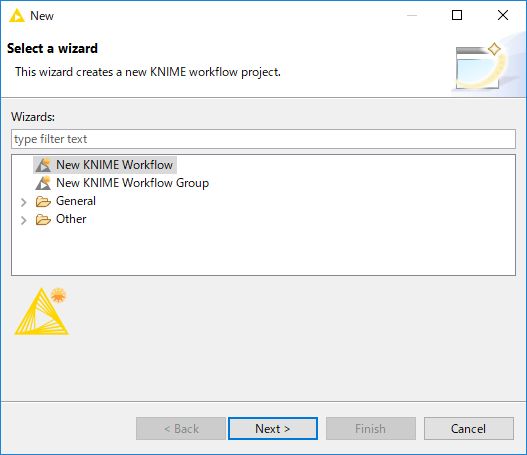
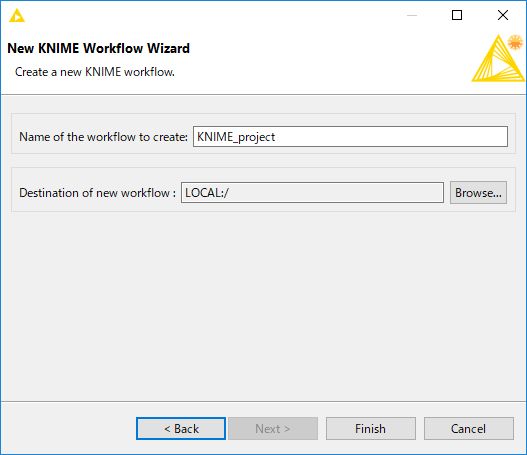
「Create a new workflow」ダイアログの「Workflow name」に任意のワークフロー名(デフォルトは「KNIME_project」)を入力します。入力が終わったら「Create」ボタンをクリックします。
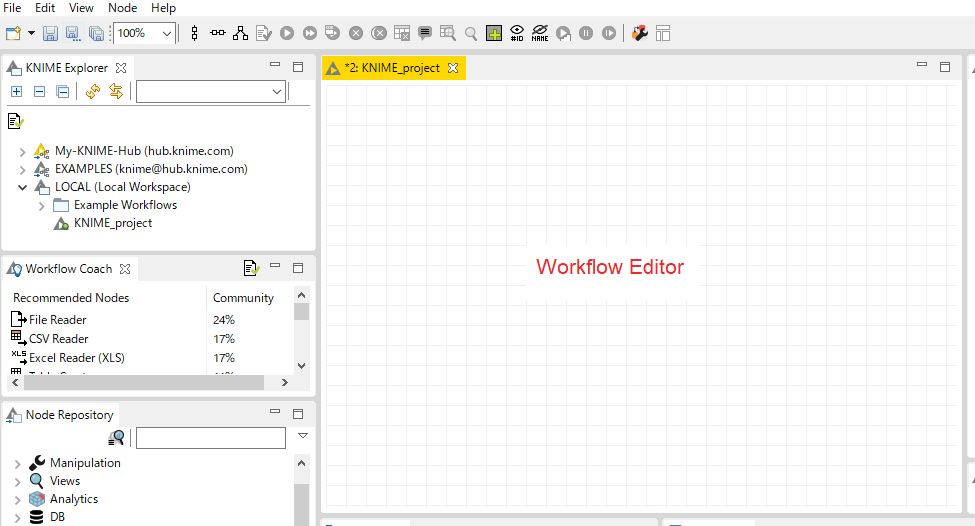
下記の画面が表示されることを確認します。これでプロジェクト作成は完了です。
3. ワークフローの作成
-
事前設定
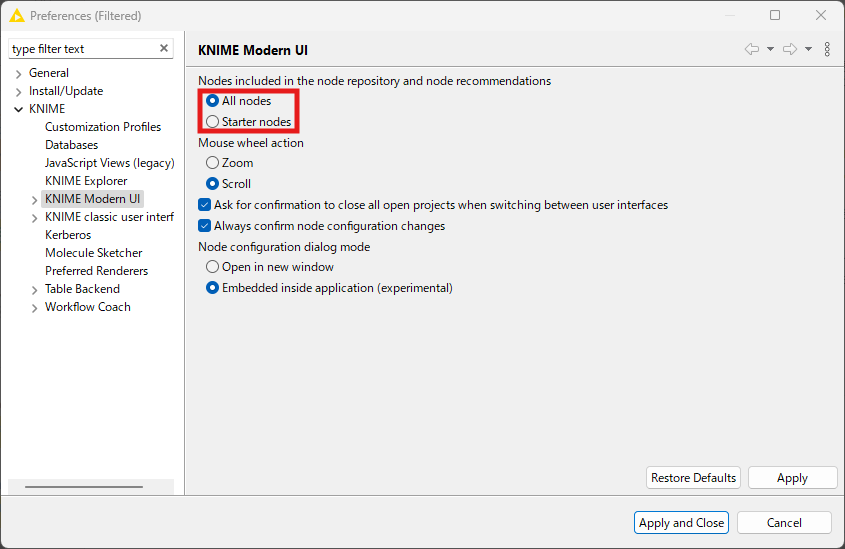
画面右上のメニューから「Preferences」をクリックし、表示される画面で KNIME Modern UI > Nodes included… の設定を「Starter nodes」から「All nodes」に変更します。
-
データの読み込み
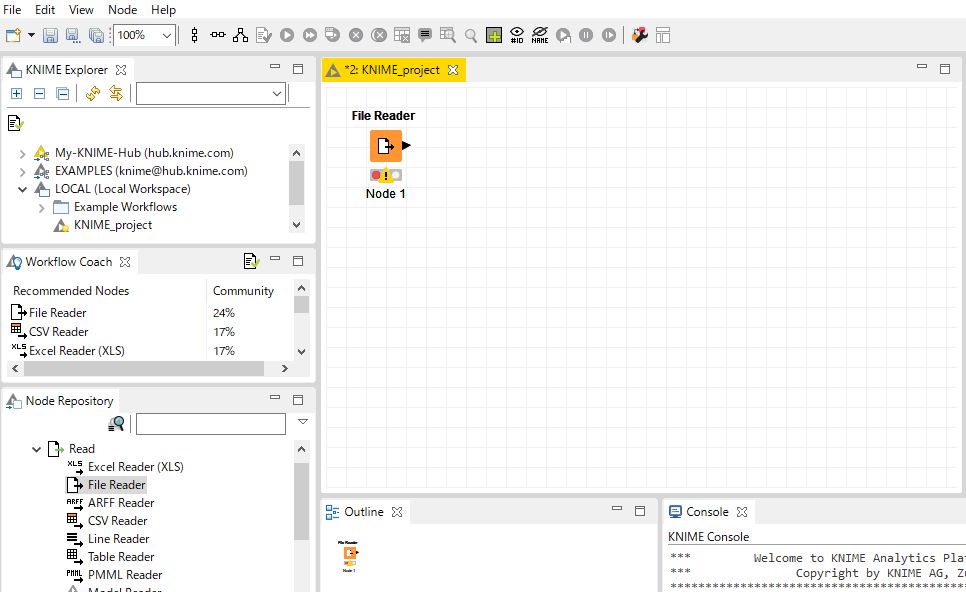
「Nodes」から「File Reader」ノードを選択し、ダブルクリックまたは「Workflow Editor」にドラッグ&ドロップし、ノードを配置します。ノードの信号マークは赤色になっていますが問題ありません。
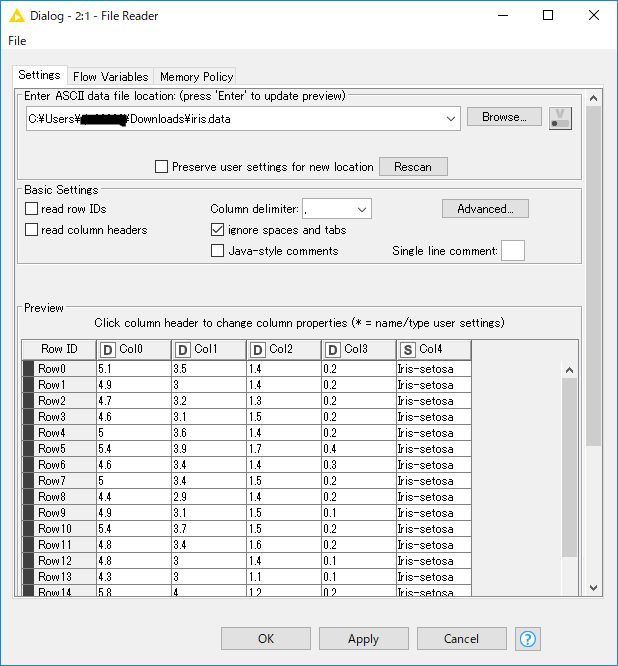
配置した「File Reader」ノードをダブルクリックするとノードの設定ダイアログが起動されます。「Input location」の「Browse」ボタンをクリックし、先ほどダウンロードした iris.data を開くと、ノード設定画面の「Preview」にファイルの内容が表示されます。ヘッダーが含まれていないため、画面中央左の「Has colummn header」のチェックを外し、「OK」ボタンをクリックします。
「File Reader」ノードを右クリックし、メニューから「Execute」を選択もしくは、ノード上部の「Excecute」ボタンをクリックすると処理実行されます。処理が完了すると、ノードの信号マークが青色に変わります。
配置した「File Reader」ノードをクリックすると、画面下部の「File Table」タブに読み込み結果が表示されます。
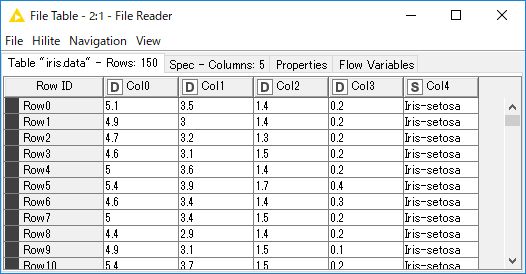
-
列名の編集
今度は「Nodes」から「Column Renamer」ノードを配置します。配置済みの「File Reader」ノードの出力ポートをクリック&ドラッグすると線が表示されるので、そのまま「Column Renamer」の入力ポートまで引っ張ってドロップすると、ノード同士が接続されます。

配置した「Column Renamer」ノードをダブルクリックして設定ダイアログを起動します。ダイアログの左側で列名を選択し、右側に入力することで列名を編集することができます。左側「Column」下のプルダウンメニューから「Column0」を選択し、右側「New name」に「sepal length」と入力します。
「Add column」をクリックすると入力欄が追加されるため、同様に「Column1~Column4」をそれぞれ「Column1」→「sepal width」、「Column2」→「petal length」、「Column3」→「petal width」、「Column4」→「class」と登録し、「OK」をクリックして設定ダイアログを閉じます。

「Column Renamer」ノードを右クリックし、メニューから「Execute」を選択し処理を実行します。実行完了した「Column Renamer」ノードをクリックし、下部に表示されるテーブルの列名が変更されていることを確認します。
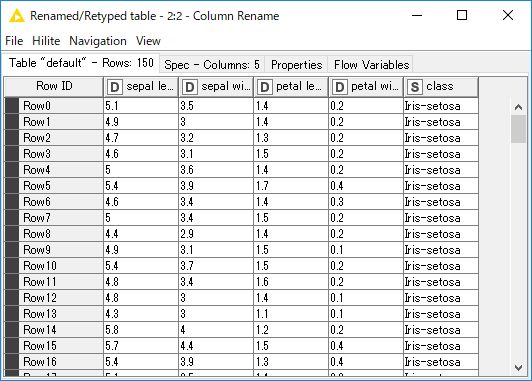
-
統計情報の表示
実行完了した「Column Renamer」ノードをクリックし、下部の「Statistics」を選択すると、統計情報(最大値、最小値、標準偏差など)が表示されます。
-
色情報の付加
「Nodes」から「Color Manager」ノードを配置し、「Column Renamer」ノードの出力ポートと接続します。接続すると「Color Manager」ノードの信号マークに警告が表示されます。
配置した「Color Manager」ノードをダブルクリックして設定ダイアログを起動します。自動で「class」列の「Iris-setosa」→緑色、「Iris-versicolor」→赤色、「Iris-virginica」→茶色 が設定されています。そのまま「OK」ボタンをクリックしてダイアログを閉じます。
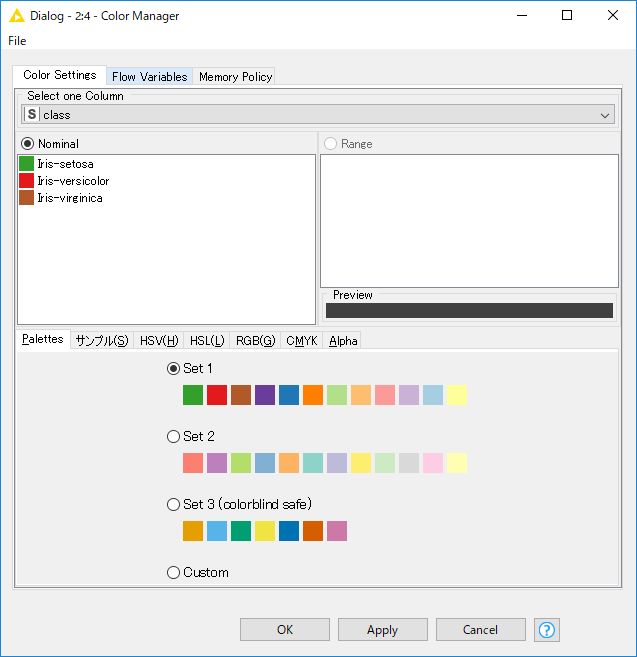
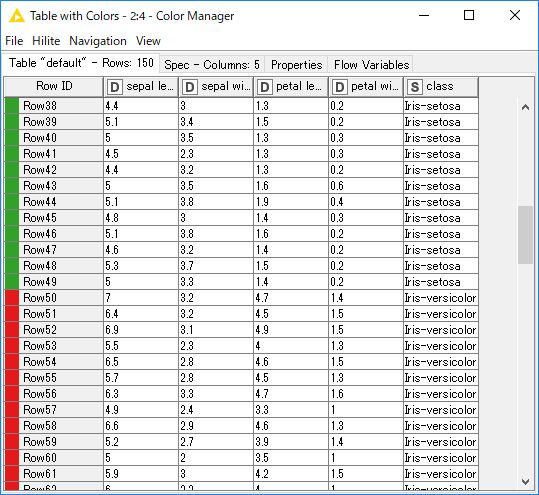
「Color Manager」ノードを実行します。処理が完了すると、下部の「Table」に色付きのテーブルが表示されます。
-
散布図マトリックスの作成
「Nodes」から「Scatter Plot Matrix」ノードを配置し、「Color Manager」ノードの出力ポートと接続します。接続すると「Scatter Prot Matrix」ノードの信号が黄色に変わります。
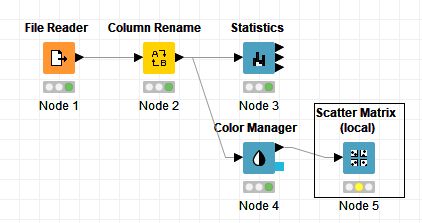
「Scatter Matrix」ノードをダブルクリックして設定ダイアログを開き、「Includes」に設定されている「petal width」と「class」を「Excudes」に設定し、「Save & execute」をクリックすると、散布図マトリックスが表示されます。右側のメニューで設定を動的に変更することができます。

-
決定木モデルの作成
「Nodes」から「Partitioning」ノードを配置し、「Column Renamer」ノードの出力ポートと接続します。
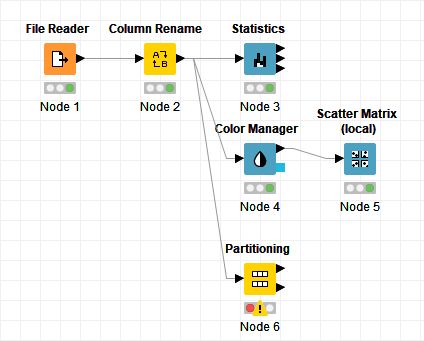
「Partitioning」ノードをダブルクリックして設定ダイアログを開き、「Relative[%]」を選択してテキストボックスに「80」を入力し、「OK」ボタンをクリックします。
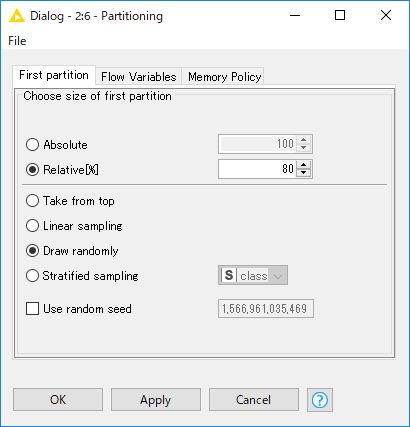
「Partitioning」ノードを実行します。処理が完了したら「Partitioning」ノードをクリックし、下部に「First partition(as defined in dialog)」と「Second partition(remaining rows)」が存在すること、iris.data が「First partition」テーブルに80%のデータ(Rows:120)、「Second partition」テーブルに残りの20%のデータ(Rows:30)が割り振られていることを確認します。
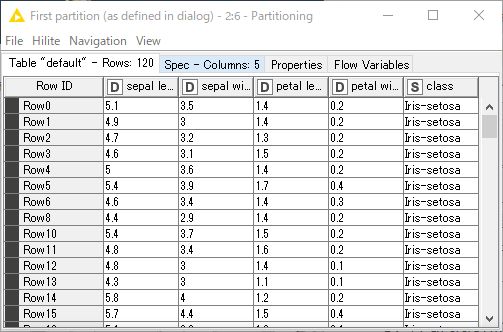
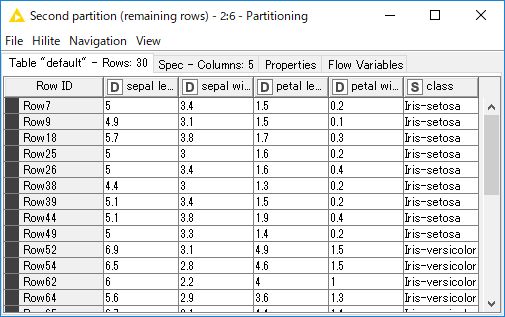
「Nodes」から「Decision Tree Learner」ノードを配置し、「Partitioning」ノードの出力ポート(上側:First partition)と接続します
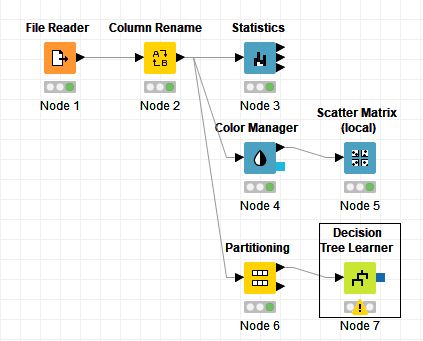
「Decision Tree Learner」ノードをダブルクリックして設定ダイアログを開き、「Class column」に「class」列が指定されていることを確認し、「OK」をクリックします。
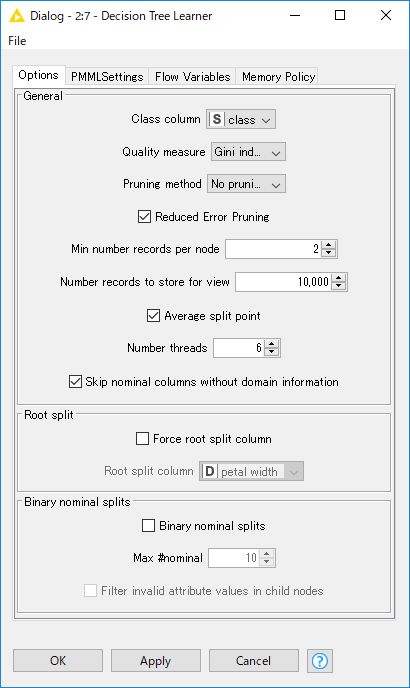
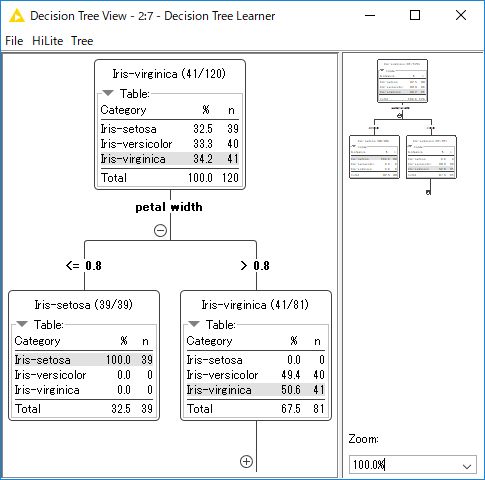
「Decision Tree Learner」ノードを実行します。処理が完了したら「Decision Tree Learner」ノードを右クリックし、メニュー上段の「Open view」を選択または、ノードにマウスフォーカス時に表示される「Open view」ボタンをクリックすると作成した決定木モデルが表示されます。
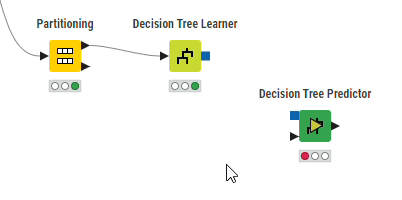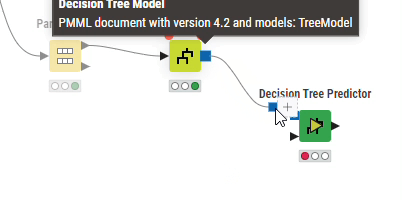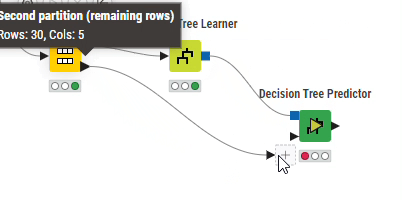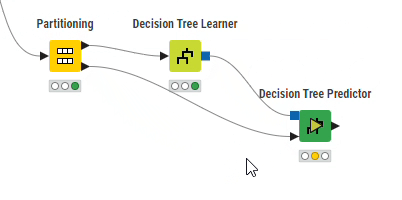
「Nodes」から「Decision Tree Predictor」ノードを配置し、「Decision Tree Predictor」ノードの入力ポート(上側:青四角)と「Decision Tree Learner」ノードの出力ポートを、ノードの入力ポート(下側:黒三角)と「Partitioning」ノードの出力ポート(下側:Second partition)とそれぞれ接続します。
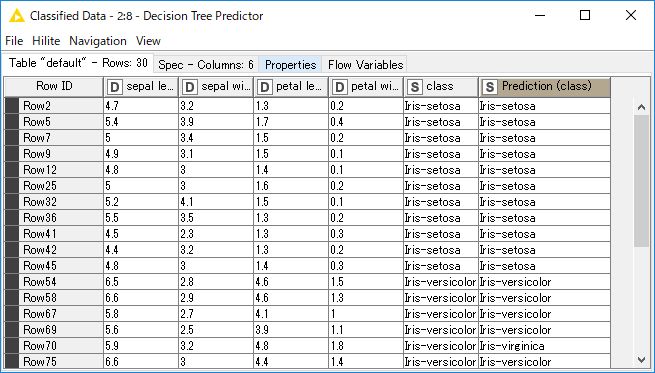
「Decision Tree Predictor」ノードを実行します。処理が完了したら「Decision Tree Predictor」ノードをクリックすると、メニュー最下部の「Classified Data」を選択すると予測結果(Prediction 列)を含むテーブルが表示されます。
4. 仕上げ
-
各ノードを選択すると表示される文字列「Add comment」をダブルクリックするとコメントが入力できるので、コメントを入力して完成です。


作成したワークフローを、もっと便利に活用するには?
デスクトップ版で作成したワークフローは、自分のPCで実行するだけでなく、
KNIME Business Hub(サーバー版)へアップロードすることで、チーム全体の資産として活用できます。
💻 デスクトップ版の課題
- ❌ 毎回手動で実行ボタンを押す必要がある
- ❌ ファイルで共有するとどれが最新かわからない
- ❌ 自分のPCを起動していないと動かない
▼
KNIME Business Hub で解決 🏢 サーバー版でできること
- ⭕ スケジュール機能で夜間に自動実行
- ⭕ Webブラウザ画面(アプリ)として公開
- ⭕ 権限管理された安全な共有
5. KNIME AI Assistant
-
K-AI(KNIME AI Assistant)はチャット形式で、ユーザーの質問や指示に応答するアシスタント機能です。KNIMEの機能に関する内容だけではなく、データ分析全般についてもサポートしており、AI人材の教育用としても活用いただけます。
詳細については下記の記事にて紹介しておりますのでぜひこちらもお試しください。AI時代を加速する新機能「K-AI(KNIME AI-Assistant)」!KNIMEでデータ活用をもっと身近で簡単に
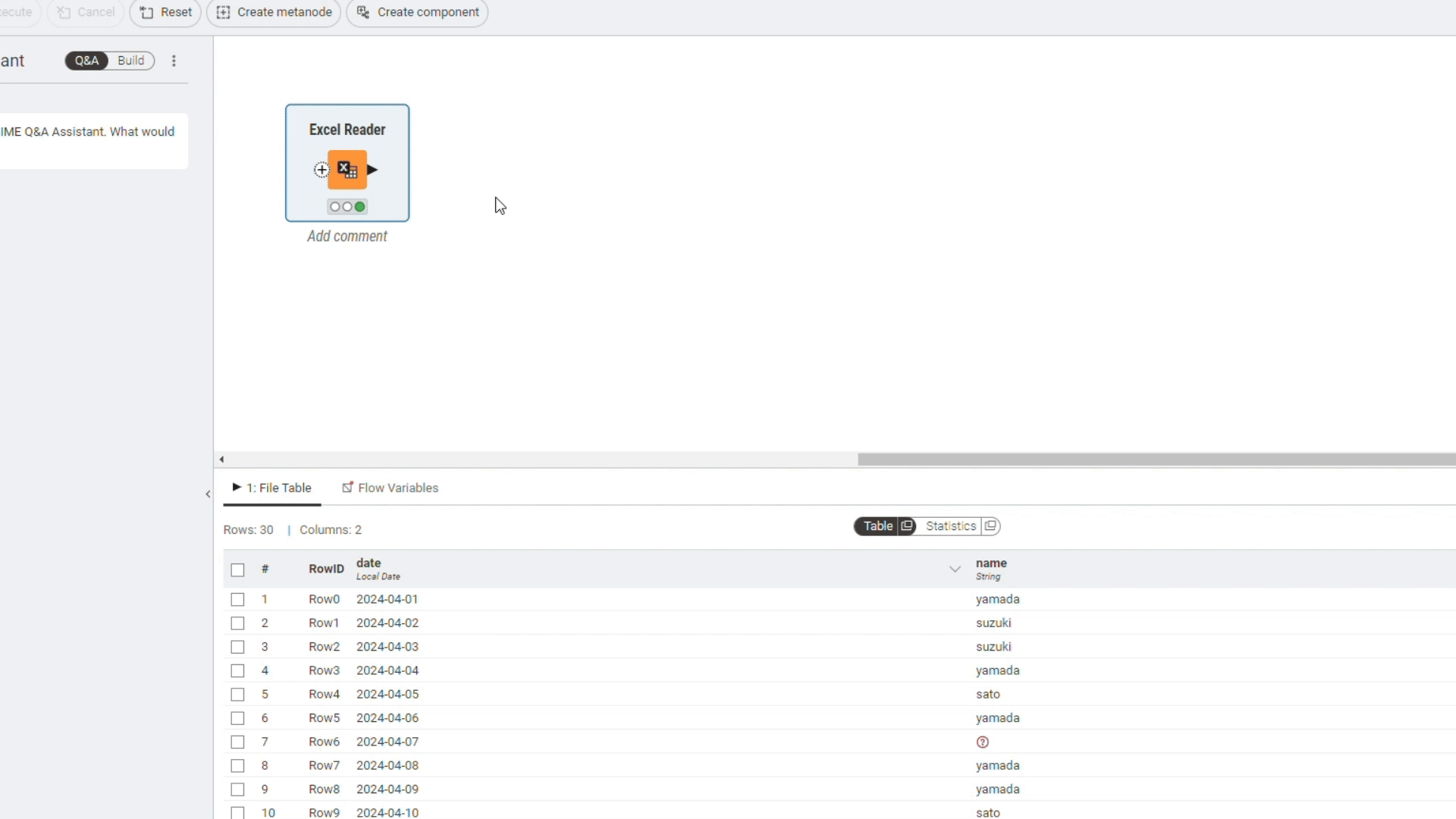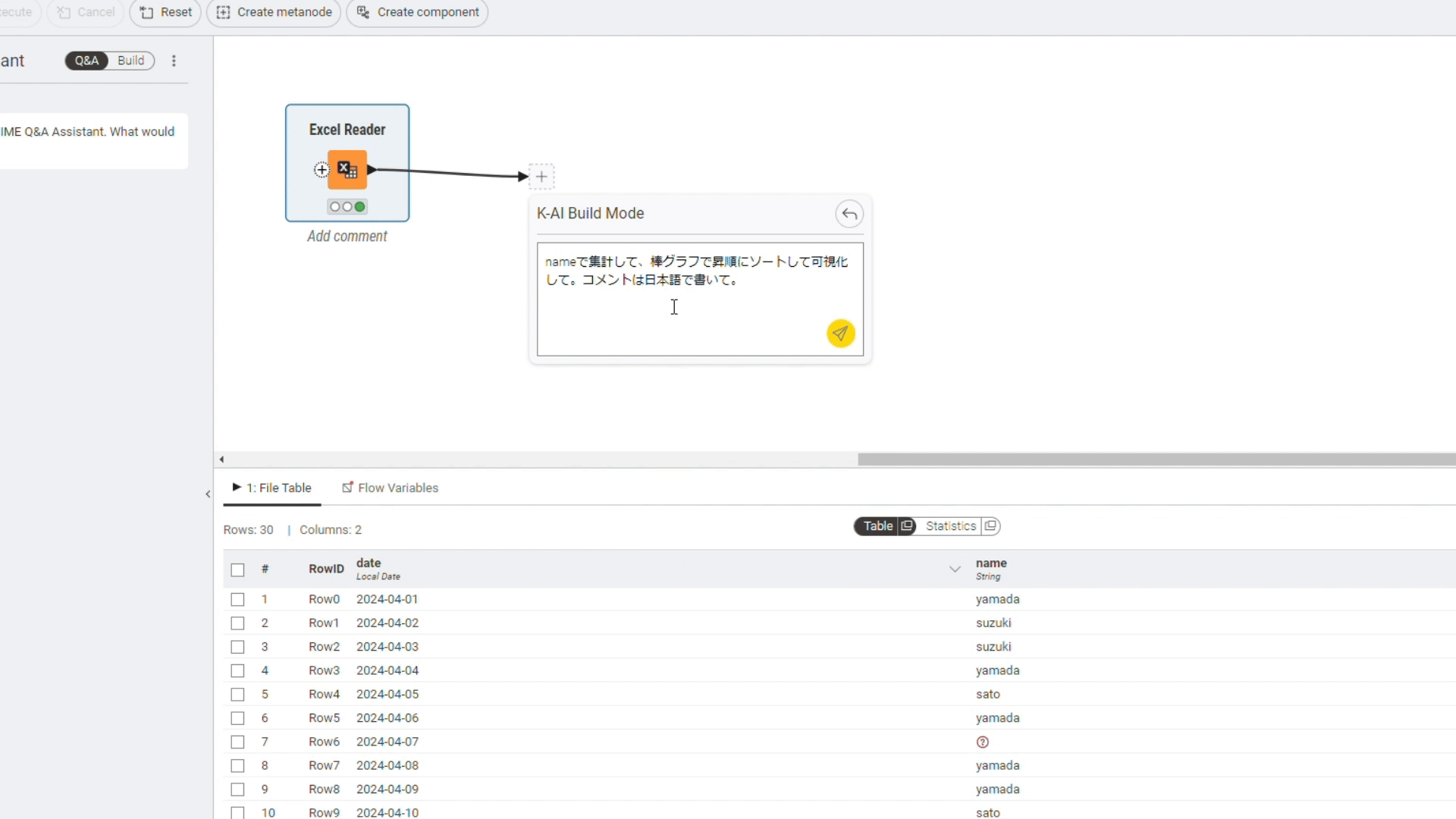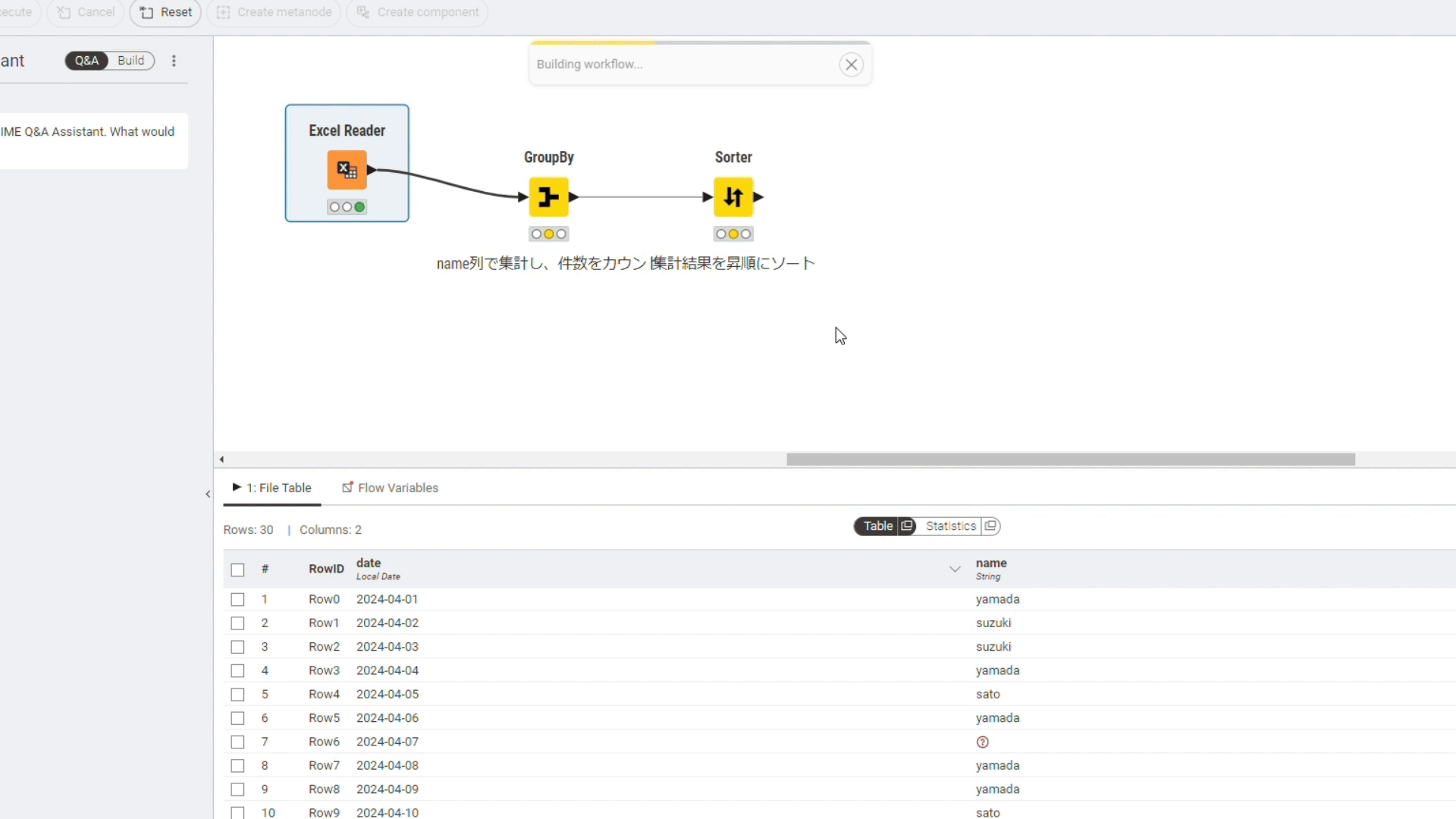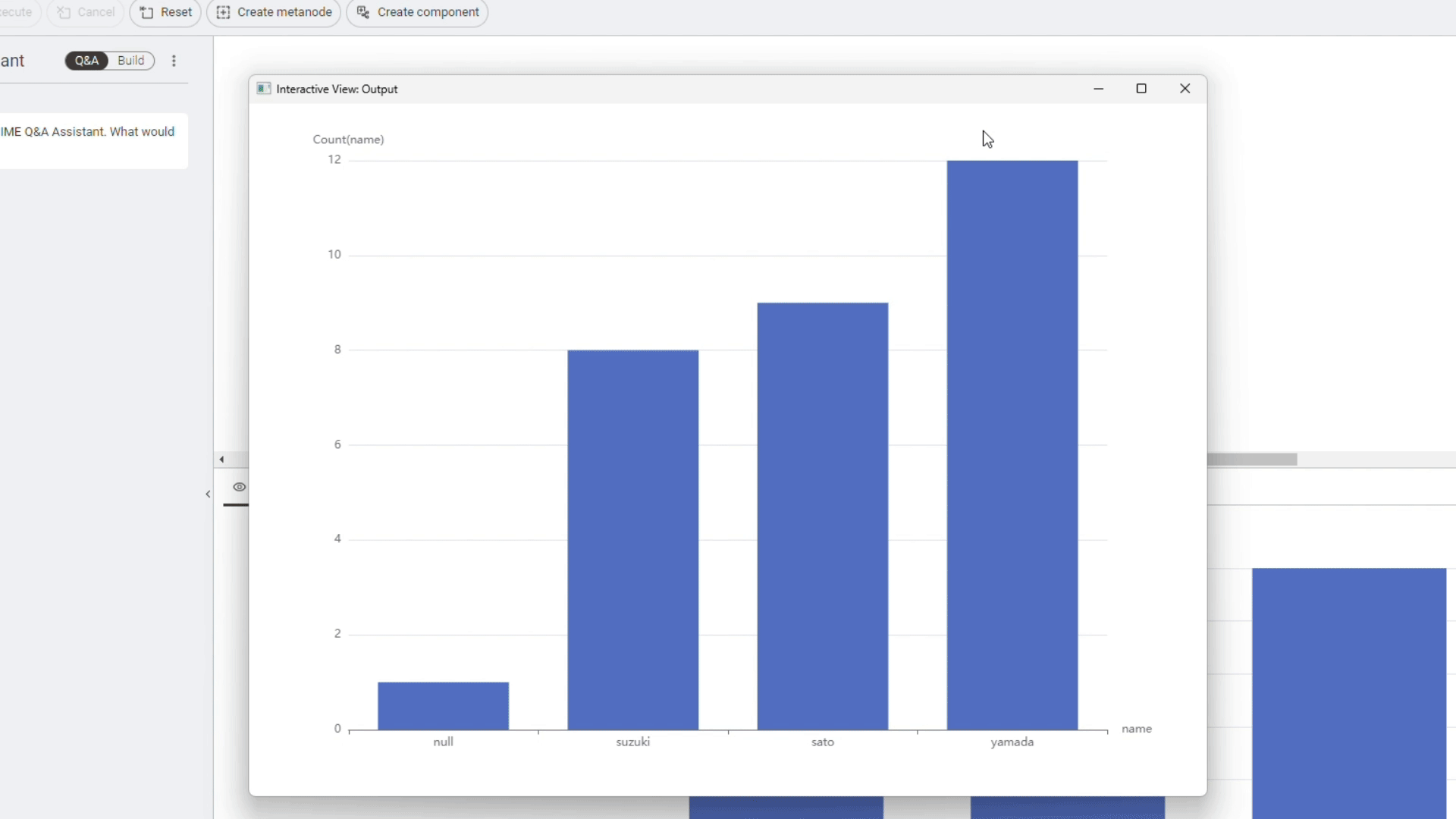
6. 機械学習自動化ワークフロー
-
KNIMEではご自身で機械学習アルゴリズムを活用した予測モデルをワークフローとして構築いただくことも可能ですが、弊社にて誰でも簡単に予測モデルを構築するためのワークフローを「機械学習自動化パッケージ」として提供しております。
こちらから無償でトライアル版ワークフローをお試しいただけますので、ぜひお気軽にお試しください。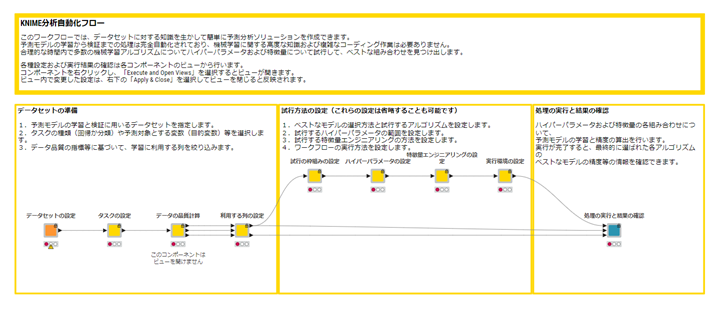
KINMEトレーニングサービス
弊社エンジニアによるKNIMEのハンズオントレーニングで、KNIMEの利用開始をサポート
このサイトでは、クッキー (cookie)などの技術を使用して取得したアクセス情報等のユーザ情報を取得しております。
この表示を閉じる場合、プライバシーポリシーに同意いただきますよう、お願いいたします。