

ブログ

最新情報をお届けします。

機械学習のためのガイド付き自動化 パートII
著者:Paolo Tamagnini、Simon Schmid、and Christian Dietz
原文:https://www.knime.com/blog/guided-automation-for-machine-learning-part-ii
この記事は、「機械学習のためのガイド付き自動化」という記事のフォローアップです。今回は、Webブラウザーアプリケーションの実行中に舞台裏で使われている技術とアルゴリズムをより詳細に説明し、機械学習ライフサイクルの自動化のためのソリューションを提案します。
目次
「KNIME」を使用した半自動機械学習のためのWebベースの青写真の実装
機械学習自動化の代償は、ブラックボックスのようにモデルに対するコントロールができなくなることです。
この代償は、明確に定義され範囲の限定されたデータサイエンスの問題には許容できるかもしれませんが、より多様な領域の、より複雑な問題に対しては足かせとなってしまうかもしれません。
このような場合、エンドユーザーとある程度対話できることが望ましいです。機械学習の自動化に対するこの柔軟なアプローチは、KNIMEを使ったガイド付き自動化によって実現されます。
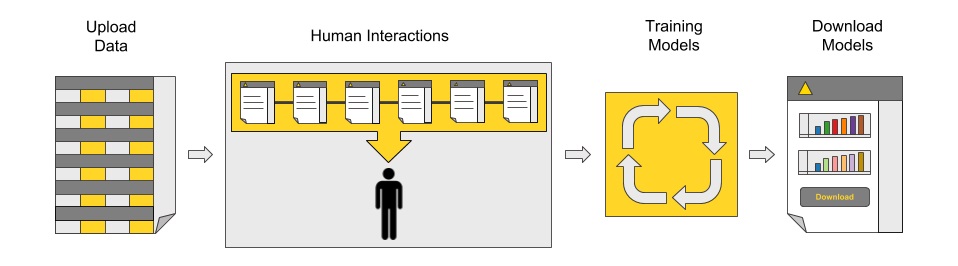
図1:ガイド付き自動化の青写真の背後にある主なプロセス
バックグラウンドで実行されるシステムは非常に複雑であるため、完全にゼロから作成するのは容易ではありません。
このプロセスを支援するために、機械学習分類モデルの自動作成とトレーニング用の対話型アプリケーションの青写真を作成しました。
青写真は「KNIME Analytics Platform」で開発されており、KNIME Community Workflow Hubで入手できます。
Webブラウザからのガイド付き自動化
Webブラウザから「KNIME Server」を介して、ガイド付き自動化の青写真がどのように表示されるかを見てみましょう。
最初に、次のような一連のステップが表示されます。
・データをアップロードする
・目的変数を選択する
・不要な特徴を削除する
・トレーニングする1つ以上の機械学習アルゴリズムを選択する
・オプションでパラメータの最適化と機能設計の設定をカスタマイズする
・実行プラットフォームを選択する
これらはすべて以下の図2に要約されています。

図2:Webブラウザーでのガイド付き自動化の青写真
データの前処理、機能の作成と変換、パラメータの最適化と特徴の選択、精度と計算パフォーマンスの観点からの最終的なモデルの再トレーニングと評価が完了すると、モデルのパフォーマンス基準を示すサマリページが表示されます。
こサマリページの最後には、トレーニングされたモデルの1つまたは複数をダウンロードするためのリンクがあります。
エンド・ユーザーの操作性については、この「機械学習自動化のためのガイド付き分析」デモで確認してください。
機械学習自動化のためのワークフロー
機械学習自動化のためのワークフローは 、こちらから入手できます。
ワークフローを「KNIME Analytics Platform」にインポートし、必要に応じてカスタマイズして、「KNIME Server」のWebブラウザーから実行できます。
このビデオでは、ワークフローにアクセスして「KNIME Examples Server」から「KNIME Analytics Platform」にインポートする方法について詳しく説明します。
また、青写真のワークフローを図3に示します。
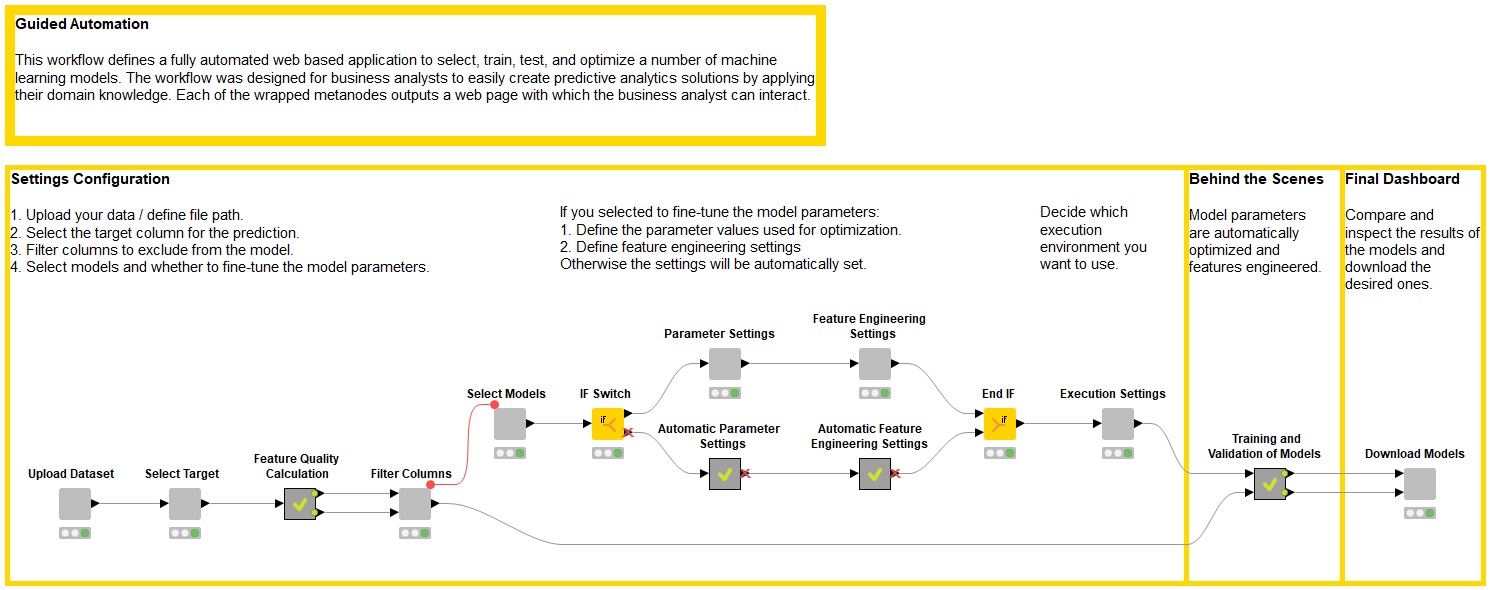
図3:必要なすべての手順とWebページを実装するガイド付きの自動化ワークフロー
このワークフローの中で、3つのフェーズが確認できます。
構成の設定:アップロード、選択、微調整、自動実行
舞台裏:データ準備、モデルのトレーニング
最終的なダッシュボード:モデルの比較とダウンロード
①アップロード、選択、微調整、自動実行
ワークフローの最初の部分では、ライトグレーの各ノードがビュー (アクション要求を含むWebページ) を生成します。
Webブラウザを介して「KNIME Server」上でワークフローを実行する場合、これらのWebページはエンドユーザーに設定ポイントや分析プロセスの対話ポイントを多数紹介します。
データセットファイルのアップロード、目的変数の選択、および特定の特徴のフィルタリングのためのノードが配置されているのが確認できます。
データ列は、適合性または専門家の知識に基づいて除外できます。適合性は列の品質の尺度です。
この尺度は列内の欠損値の数とその分布に基づいています。欠落した値が多すぎる列、または定数や分散値が多すぎる列はペナルティを受けます。さらに、列を手動で削除して、データの漏洩を防止できます。
その後、トレーニングする機械学習モデルを選択し、オプションでパラメータの最適化と特徴エンジニアリングの設定を導入、最後に実行プラットフォームを選択できます。
これらのノードの実行によって生成されるWebページのシーケンスを図2に示します。
②データ準備とモデルのトレーニング
次に、バックグラウンドで数値計算が行われます。これがガイド付き自動化アプリケーションの心臓部です。これには次の操作が含まれます。
・欠損値補完および、異常値検出
・モデルパラメータの最適化
・特徴選択
・最終的な最適化モデルのトレーニングまたは、再トレーニング
すべての設定が定義された後、アプリケーションはバックグラウンドで選択されたすべてのステップを実行します。
データの分割
最初に、データセットをトレーニングセットとテストセットに分割し、目的変数に対して層化抽出法で 80対20 に分割します。
機械学習モデルはトレーニングセットでトレーニングされ、テストセットで評価されます。
データの前処理
ここで、欠損値には列ごとの平均値または最頻値が代入されます。
これより前に選択された場合、外れ値は四分位範囲(IQR)技術を用いて検出され、最も近い閾値が設定されます。
パラメータの最適化
パラメータの最適化プロセスは、選択されたハイパーパラメータのセットに対してグリッド探索を実施します。
グリッドサーチの粒度は、ハイパーパラメータのモデルとタイプによって異なります。
各パラメータセットを4回の交差検証スキームでテストし、平均精度でランク付けします。
特徴エンジニアリングと特徴の選択
特徴エンジニアリングでは、以前の設定に従って多数の人工的な列が作成されます。4種類の列変換を適用できます。
・単一列での単純な変換((ex、x 2、x 3、tanh(x)、ln(x))
・カラムのペアと算術演算の組み合わせ
・主成分分析(PCA)
・クラスタ距離変換(データを選択した特徴によってクラスタ化し、選択したクラスタ中心までの距離を各データ点について計算する)
モデルの再トレーニングと評価
最後に、最適ハイパーパラメータと最適入力特徴集合を用いて、選択した機械学習モデルの全てを最後にトレーニングし、精度測定のためにテストで再評価しました。
③最終的なダッシュボード:モデルの比較とダウンロード
ワークフローの最後の部分では、ランディング・ページにビューが作成されます。
「Download Models」 という名前のノードには、パッケージ化されたJavaScriptベースのビューが含まれており、最終的なランディング・ページに表示されるプロット、チャート、ボタンおよび説明を生成します。
ROC曲線、精度尺度、ゲインチャートまたはリフトチャート、および混同行列がテストセットで計算され、この最終ランディングページに表示されて、精度メジャーが比較されます。
モデルの実行速度はトレーニング中および展開中に評価されます。展開実行速度は、1つの入力に対して予測を実行するための平均速度として測定されます。
したがって、2つの棒グラフはそれぞれ、モデルのトレーニング時間(秒単位)と単一の予測を生成する平均時間(ミリ秒単位)を示します。
すべてのダッシュボードビューは対話型です。プロット設定を変更し、データの視覚化をその場で調べることができます。
また、同じノードがページの最後にリンクを生成し、将来の使用のためにトレーニングされた1つ以上のモデルをダウンロードします。
ガイド付き機械学習のための簡単にカスタマイズできるワークフロー
機械学習のためのガイド付き自動化の旅の終わりに達しました。
2記事にわたり、機械学習のためのガイド付き自動化とは何か、半自動(ガイド付き)機械学習アプリケーションのための私たち自身の解釈、そして必要なステップを示しました。
また、「KNIME Analytics Platform」を介して青写真を実装しました。これは無料でダウンロードでき、あなたのニーズに合わせてカスタマイズでき、自由に再利用できます。
さらに、関連するGUIおよび、分析手順を紹介した後、Webブラウザビューの背後にあるアプリケーションを実装するワークフローを示しました。
このワークフローはすでにバイナリおよびマルチクラスの分類に対応しており、ドキュメントの分類問題や時系列分析など、他の分析問題にも簡単にカスタマイズして適用できます。