

ブログ

最新情報をお届けします。

機械学習のためのガイド付き自動化
著者:Paolo Tamagnini, Simon Schmid, and Christian Dietz
原文:https://www.knime.com/blog/how-to-automate-machine-learning
データサイエンスのライフサイクルを完全に自動化することは可能でしょうか?
また、蓄積されたデータから機械学習モデルを自動的に構築することは実現できるものでしょうか?
実際、ここ数カ月の間に、データサイエンスプロセスのすべてまたは一部を自動化すると主張するツールが数多く登場しています。
どのような仕組みになっているのでしょうか?自分で作れるのでしょうか?
これらのツールのいずれかを採用した場合、それを自分自身の問題やデータセットに適応させるには、どの程度の作業が必要になりますか?
通常、機械学習を自動化することの代償は、ブラックボックスのようにモデルをコントロールできなくなることです。
これは、明確に定義された領域上の制限された事象に対しては問題ないかもしれませんが、より広範な領域の、より複雑な問題に対する足かせとなってしまう可能性があります。
このような場合、エンドユーザがある程度コントロールできることが望ましいのです。
「KNIME」では、機械学習の自動化に対してより柔軟なアプローチを取っています。
私たちの半自動化、つまりガイド付き自動化の特殊なインスタンス「導かれた分析」は、完全に自動化されたウェブの選択を通じてユーザーを導くためのアプリケーション、トレーニング、テスト、および機械学習モデルの数の最適化の使用をガイドします。
このワークフローは、ビジネスアナリストがドメインの知識を適用して予測分析ソリューションを簡単に作成できるように設計されています。
この記事では、このアプリケーションをWebブラウザーから実行する場合のステップを、ビジネスアナリストの視点から説明します。
フォローアップ記事では、舞台裏での実装を示し、特徴エンジニアリング、機械学習、異常値検出、特徴選択、パラメータ最適化、およびモデル評価に使用されるテクニックを詳細に説明します。
目次
機械学習自動化への第一歩 ~自動化に向けたアシスタントツール~
ガイド付き自動化では、プロセスを完全に自動化することを目的としません。
その代わりに、モデリングプロセス全体を通じて必要に応じてフィードバックを得られるようにします。
ガイド付き自動化アプリケーションは、データサイエンティストによってエンドユーザー向けに開発されています。実現のためには次のものが必要です。
- エンドユーザーにとっての使いやすさ(たとえば、Webブラウザからの実行)
- 設定を収集して結果を表示するための一連のGUI
- スケーラビリティのオプション
- バックグラウンドで実行される柔軟で拡張性に優れた機敏なデータサイエンスソフトウェアアプリケーション
柔軟で拡張性に優れた機敏なデータサイエンスソフトウェアとは、複雑なデータと機械学習操作の組み合わせを可能にします。
これは、他のデータサイエンスツール、データ型、およびデータソースとの容易な統合を可能にするデータサイエンスアプリケーションを意味します。
一般に、ガイド付き自動化アプリケーションは、多くの種類の機械学習モデルの作成を自動化することができます。
この場合、一般的な分類モデルを作成するために、データサイエンスサイクルの次の部分を自動化する必要があります。
- データ準備
- 特徴エンジニアリング
- パラメータ最適化
- 特徴選択
- モデル訓練
- モデル評価
- モデル展開
最終的なアプリケーションがエンドユーザーには単純に見えるかもしれませんが、バックグラウンドで実行されているシステムは非常に複雑であるため、完全にゼロから作成するのは容易ではありません。
このプロセスを支援するために、機械学習分類モデルを自動的に作成するための対話型アプリケーションの青写真を作成しました。
この青写真は「KNIME」で開発されたもので、私たちの公開リポジトリで公開されています。
機械学習のガイド付き自動化のための青写真
ガイド付き自動化の青写真の背後にある主な概念には、いくつかの基本的なステップが含まれています。
- データアップロード
- 人間の対話によるアプリケーション設定の定義
- 設定に基づく自動モデルトレーニングおよび最適化
- パフォーマンスの概要とモデルのダウンロードを含むダッシュボード
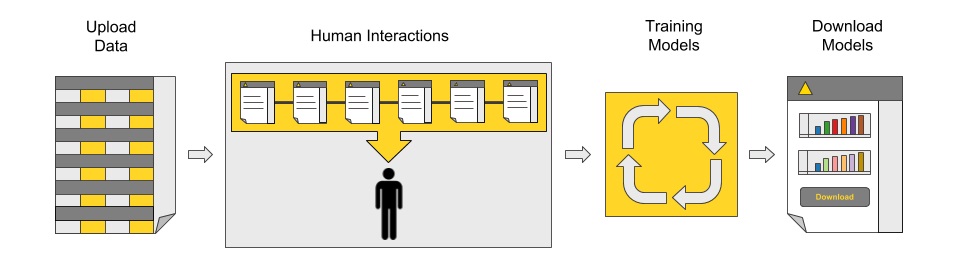
図1:ガイド付き自動化の青写真の背後にある主なプロセス
青写真に実装されている現在のプロセス(図1)は、標準的な予測分析の問題に適用されます。
しかし、データの問題に対処する場合、標準的なものがそのまま適用されることはほとんどありません。
多くの場合、特殊なデータ型、データ構造、または既存の情報のために、カスタム処理を入力データに適用する必要があります。
場合によっては、トレーニングデータセットとテストデータセットが特定のルール (時間順序など) に従う必要があります。
図2に、カスタムデータの前処理やトレーニングデータ/テストデータ分割など、前のプロセスのカスタマイズの可能性を示します。
これらのカスタマイズは、「KNIME」の青写真に簡単に適用できます。
ビジュアルプログラミングフレームワークのおかげで、コーディングは必要ありません。
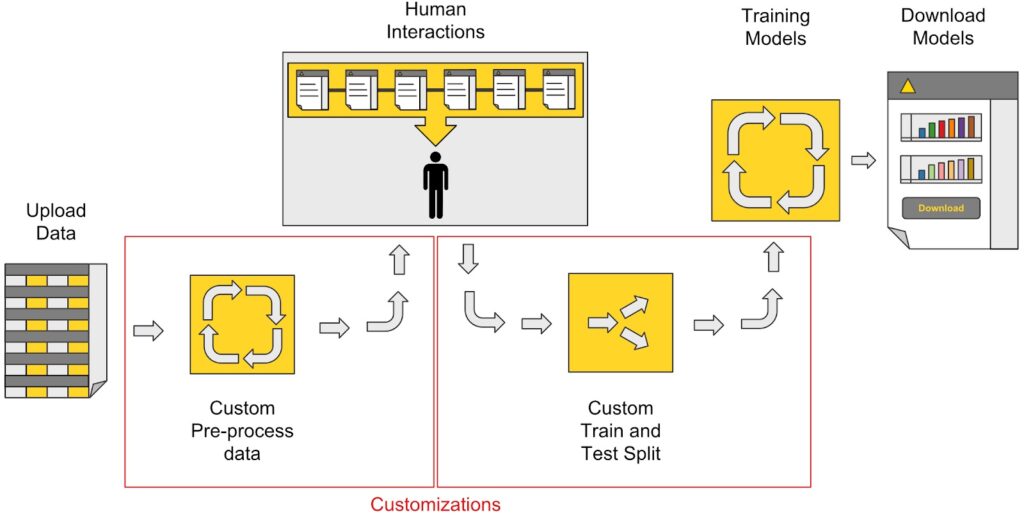
図2:ガイド付き自動化のカスタマイズ
機械学習のガイド付き自動化:Webブラウザで段階的に
機械学習のガイド付き自動化の青写真がKNIME Server経由のWebブラウザからどのように見えるかを見てみましょう。 最初に、一連のインタラクションポイントが表示されます。
- データをアップロードする
- ターゲット変数を選択する
- 不要な特徴を削除する
- トレーニングする1つ以上の機械学習アルゴリズムを選択する
- オプションでパラメータの最適化と特徴エンジニアリングの設定をカスタマイズする
- 実行プラットフォームを選択する
入力する特徴は、ビジネスアナリスト自身の専門知識や機能の関連性に基づいて削除できます。
使用した関連性の尺度は、列の欠落した値と値の分布に基づいています。
列に欠落した値が多すぎる場や値が定数である場合、または値が分散しすぎている場合は、ペナルティが適用されます。
パラメータの最適化と特徴エンジニアリングのカスタマイズはオプションです。パラメータ最適化は、カスタマイズ可能なパラメータ範囲のグリッド探索により実行されます。特徴エンジニアリングが有効になっている場合、最初に選択した特徴の組み合わせと変換が行われ、次に最終的な特徴の選択が行われます。
実行プラットフォームに関しては、ローカルマシン(デフォルト)からSparkベースのプラットフォームや他の分散実行プラットフォームまでいくつかの選択肢があります。
すべてのインタラクションポイントに使用するWebページテンプレート (下の図3に要約) には、右側に必要なタスクの説明、上部にアプリケーションフローチャートがあります。
以降のステップはグレー、過去のステップは黄色、現在のステップは黄色のフレームで表示されます。

図3:Webブラウザでのガイド付き自動化の青写真の実装
すべての設定が定義されると、アプリケーションはバックグラウンドでステップを実行します。
選択された特徴は、データの前処理(欠損値と外れ値への対処)、特徴の作成と変換、パラメータの最適化と特徴の選択、および最終的なモデルの再トレーニングと精度尺度と計算パフォーマンスに関する評価を行います。
そしてここで、ガイド付き自動化の旅が終わります。
アプリケーションは、選択された機械学習モデルを精度と実行速度の観点から比較するダッシュボードを表示します。
ROC曲線、精度尺度、ゲインチャートまたはリフトチャート、および混乱マトリックスがテストデータセットで計算され、最終ランディングページに表示されて、精度尺度(図4)が比較されます。
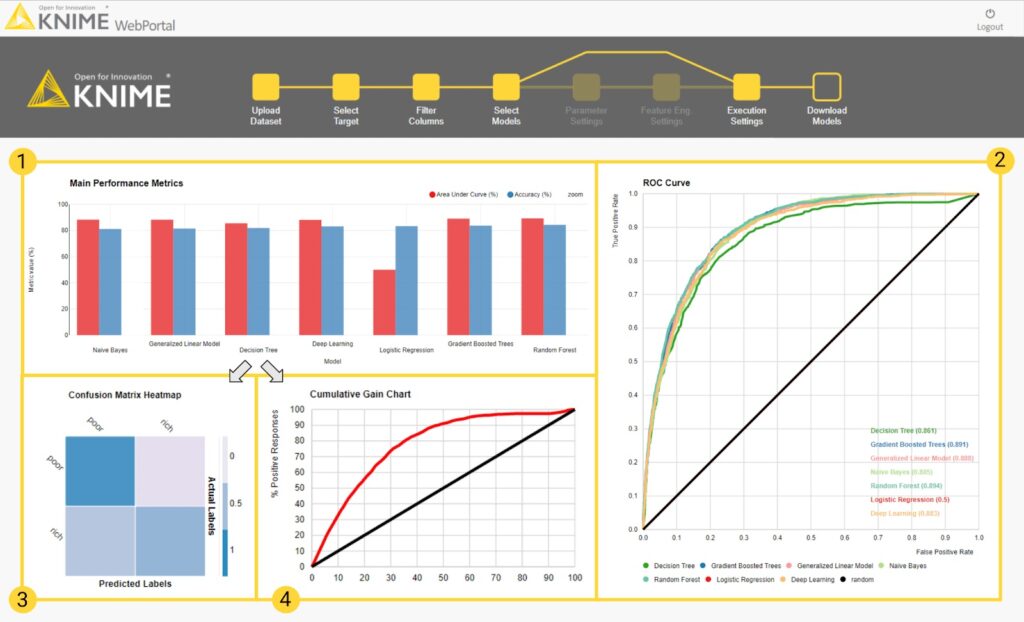
図4:ガイド付き自動化青写真の最終ページにあるダッシュボード
①精度の棒グラフ(青)とAUCスコア(赤)
②ROC曲線
③混同マトリックスヒートマップ
④累積ゲインチャート
モデルの実行速度は、トレーニング中およびデプロイメント中に評価されます。
デプロイメント実行速度は、単一入力の予測を実行するための平均速度として測定されます。
したがって、2つの棒グラフはそれぞれ、モデルのトレーニング時間(秒)と単一の予測を生成する平均時間(ミリ秒)を示します。
すべてのダッシュボード・ビューは対話型です。
プロット設定を変更し、データの視覚化をその場で探索することができます。
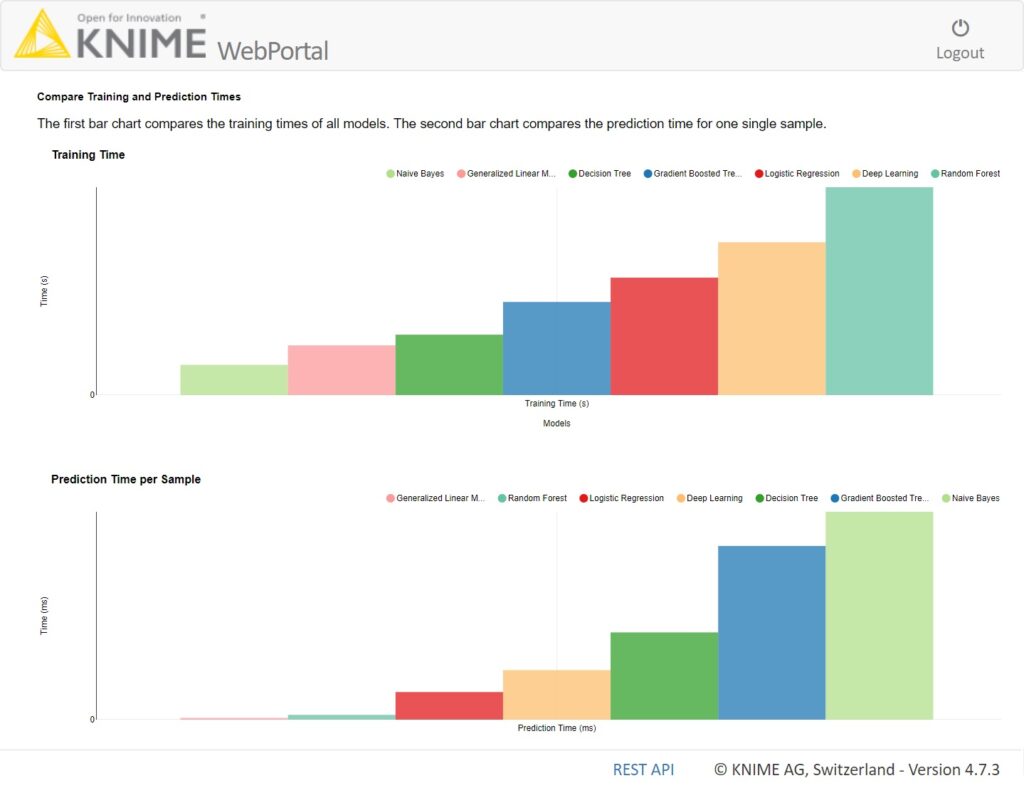
図5:実行速度を表示するダッシュボード
これで、モデルをダウンロードする準備ができました。
最終的なダッシュボードには、トレーニングされたモデルの1つ以上をダウンロードするためのリンクがあります。
ガイド付き自動化を体験するには、このデモビデオでアプリケーションの動作を確認してください。
「機械学習自動化のためのガイド付き分析。」
ビジネスアナリストのための機械学習
この記事では、機械学習のガイド付き自動化の青写真を説明し,必要なステップを示しました。
このワークフロー駆動Webアプリケーションは、半自動(ガイド付き)機械学習アプリケーションの独自の解釈を表しています。
次回の記事では、舞台裏での実装について説明します。
「KNIME」を介して実装され、この記事で説明されている青写真は、KNIME HUBで無料でダウンロードできます。
また、必要に応じてカスタマイズでき、自由に再利用できます。
Webベースのワークフローは、KNIME Server上で同じアプリケーションを実行することによって実行できます。
さて、この青写真から出発して、ガイド付き機械学習アプリケーションを作成してみましょう。
このようにして、ビジネスアナリストがWebブラウザから機械学習モデルを簡単に作成し、トレーニングできるようになります。