

KNIME Analytics Platform
KNIME Analytics Platformは、ノーコードでデータの前処理や分析を行うことができるデスクトップアプリです。オープンソースで開発されており、すべての機能を無償でご利用いただけます。
KNIME で実現できるデータ活用のステップ
エンドツーエンドの
ワークフロー構築
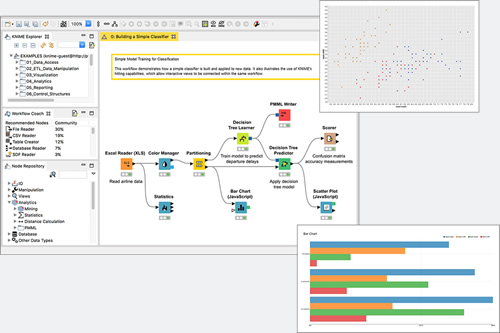
ノーコード・直感的なGUI操作でワークフローを構築します。
データの読み取りや加工、機械学習、AWSやGoogleといったクラウドサービス、またはApache Sparkへのコネクタ、R&Pythonで作成したスクリプトの取り込みなど、あらゆるワークフローを構築するために4000以上のモジュール(ノード)が用意されています。
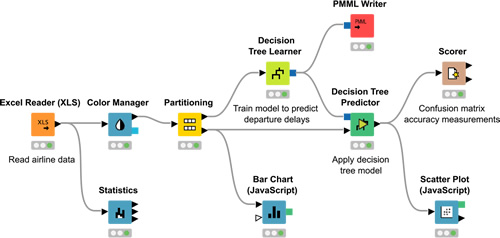
データのブレンド
単純なテキストフォーマット(CSV、PDF、XLS、JSON、XMLなど)、非構造化データタイプ(画像、ドキュメント、ネットワーク、分子など)、時系列データ等をフロー内で結合出来ます。
Oracle、Microsoft SQL、Apache Hiveなど多数のデータベースおよびデータウェアハウスに接続してデータを統合します。HDFS、S3、またはAzureからAvro、Parquet、ORCファイルもロード可能です。
Twitter、AWS S3、Google Sheets、Azureなどのソースへのアクセス機能も用意しています。
データ整形
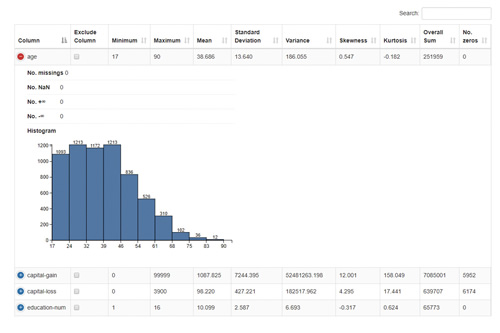
平均値、分位数、標準偏差などの統計量の算出、また統計的検定を適用して仮説を検証出来ます。次元削減、相関分析などもワークフローに組込めます。
正規化、データ型変換、および欠損値処理によってデータをクリーニングします。異常値検出アルゴリズムを使用して、範囲外の値を検出します。機械学習用にデータセットを準備するために、特徴を抽出して選択します。(または新しいものを作成します)
機械学習とAIの活用
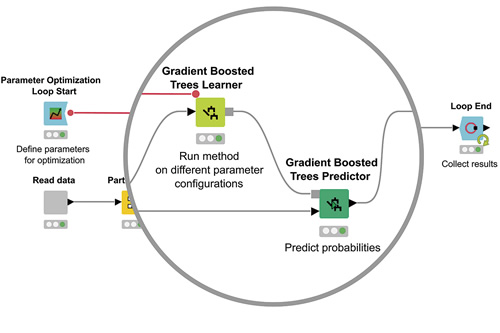
ディープラーニング、、ロジスティック回帰などの高度なアルゴリズムを使用して、分類、回帰、次元削減、またはクラスタリングのための機械学習モデルを構築出来ます。
ハイパーパラメーターの最適化、ブースティング、バギング、スタッキング、または複雑なアンサンブルの構築でモデルのパフォーマンスを最適化します。
Accuracy、R2、AUC、ROCなどのパフォーマンスメトリクスを適用してモデルの検証が出来ます。
洞察の発見と共有
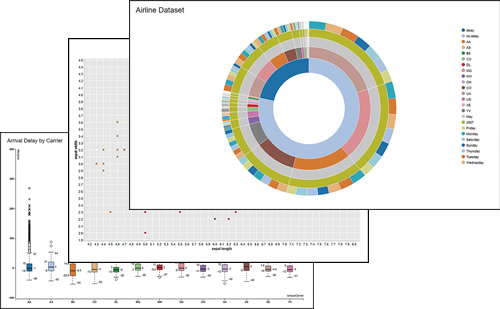
従来のチャート(棒グラフ、散布図等)と高度なチャート(平行座標、サンバースト、ネットワークグラフ、ヒートマップ等)を使用してデータを視覚化し、ニーズに合わせてカスタマイズ出来ます。
関係者に結果を共有するために、レポートをPDF、PowerPoint、またはその他の形式としてエクスポート可能です。
動的な規模拡張
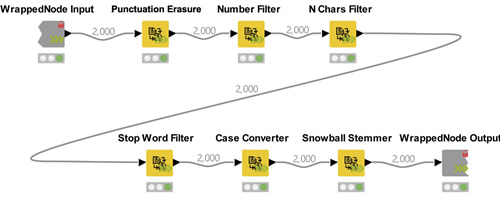
インメモリストリーミングとマルチスレッドデータ処理によってワークフローのパフォーマンスを向上出来ます。
さらに計算パフォーマンスを向上させるには、Apache Sparkでデータベース内処理または分散コンピューティングの機能が利用出来ます。
作成したワークフローを、組織の「資産」に。
KNIME Analytics Platformで構築した分析ロジックは、
KNIME Business Hub へ展開することで、チームでの共有・自動実行・Webアプリ化が可能になります。
- ・個人のPCで実行
- ・手動でのデータ処理
- ・ファイルでの共有
- ・サーバーで自動実行 (スケジュール)
- ・ブラウザで誰でも利用可能 (Webアプリ)
- ・セキュアな権限管理と共有
このサイトでは、クッキー (cookie)などの技術を使用して取得したアクセス情報等のユーザ情報を取得しております。
この表示を閉じる場合、プライバシーポリシーに同意いただきますよう、お願いいたします。