

ブログ

最新情報をお届けします。

IoT異常検知:予期せぬ事態を予測するためのデータサイエンス(前編)
著者:Rosaria Silipo (KNIME)
原文:https://www.knime.com/blog/iot-anomaly-detection-101-data-science-to-predict-the-unexpected
【製造業向け】IoT異常検知入門:予期せぬ「異常動作」や故障予知を実現するデータサイエンス(前編)
データサイエンスおよび人工知能(AI)技術は、長年にわたって様々な「予兆」や「異常」を検出するために適用されてきました。
その応用範囲は広く、以下のような分野で既に活用されています。
- IoTにおける機械部品のライフサイクル制御(予兆保全・故障予測)
- 製造ラインや店舗での行動検知・異常検知
- 生物学のDNA断片化解析
- 製薬業界での創薬プロセス
- ソーシャルメディアでの感情分析
- クレジットカード取引での不正検出
- 疫学における疾患波の予測
- ECG信号の心拍分類(医療ヘルスケア)
- セキュリティ分野での顔認識・音声認識
Webで「機械学習のユースケース」を検索すると多岐にわたる事例が出てきますが、本記事では特に「製造業・IoTにおける異常動作の検知」に焦点を当てて解説します。
一般的に、機械学習プロジェクトを成功させる鍵は「十分なトレーニングデータ(教師データ)」の存在です。
しかし、製造現場における「異常検知」には特有の課題があります。それは、「正常なデータに比べて、故障データ(異常データ)が圧倒的に少ない」という点です。これがデータサイエンスプロジェクトにおける最大の難所となります。
目次
異常検知・行動検知における機械学習の活用
機械学習アルゴリズムを適切に適用すれば、機械部品の劣化による異常動作を予測したり、サイバーセキュリティの侵害(異常な振る舞い)を即座に検出したりすることが可能です。
データサイエンスの手法は、IoTやセキュリティの分野で既に多くの実績を上げています。
例えば、「IoT」での機械学習の典型的な使用法として「需要予測」があります。
- レストランの来客数予測
- 商品の販売数予測
- 明日のエネルギー消費量予測
これらを事前に把握することで、計画的なリソース配分が可能になります。
また、ヘルスケア分野や「行動検知」の文脈でも、IoTとデータサイエンスの組み合わせは一般的です。
ウェアラブルデバイス等からリアルタイムに大量のデータを取得し、健康状態や人の動きを評価します。
そして、製造業における「IoT」の最も重要な活用法が「故障予測(予兆保全)」です。
機械の部品がいつ異常動作を起こし、メンテナンスを必要とするかを予測できれば、最適なメンテナンススケジュールを計画でき、機械の寿命を延ばし、ダウンタイム(停止時間)による甚大な損失を防ぐことができます。
高価で複雑な機械部品を扱う製造現場において、これは極めて大きなメリットです。過去の故障データ(ラベル付きデータ)が存在する場合、このアプローチは非常に強力に機能します。
異常検知の課題:過去に例のない「異常動作」を探す
しかし、「異常検知」はデータサイエンスの中でも特殊な専門分野です。
ここでの「異常」とは極めて稀な事象であり、過去のデータや現在の知識では想定できていないイベントを指します。
- 現在の知識では、いつ起こるか予測できない。
- これまでの単純な「閾値監視」などの手法では特定できない。
異常検知の難しさは、「過去に事例がなく、事前に予測もできないイベント」を探さなければならない点にあります。
一見不可能に思えるかもしれませんが、現場では頻繁に直面する課題です。
- 不正なトランザクションは滅多に発生しませんが、手口を変えて予期せず発生します。
- IoT化された高価な機械部品が、何の前触れもなく突然「異常動作」を起こし故障します。
- 心電図に、見たことのない形状の新しい不整脈が表示されます。
- 未知のサイバー攻撃により、セキュリティログに奇妙な痕跡が残ります。
これらに対しては、過去の故障例(ラベル付きデータ)に基づいた従来の教師あり学習アプローチは適用できません。
この問題を解決するのが、「正常なデータのみから学習する」というアプローチです。
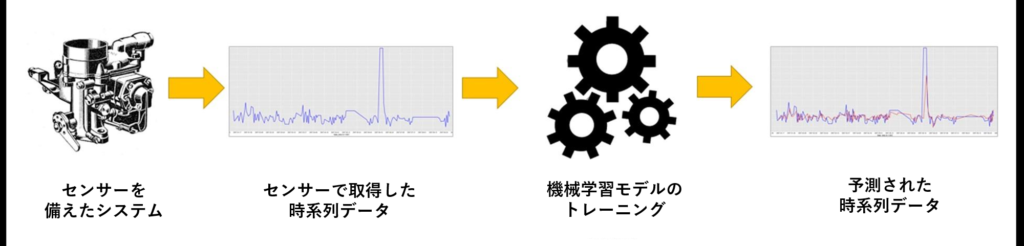
IoTデータの場合、機械コンポーネントに設置されたセンサーから時系列データが生成されます。
通常、機械部品は正常に機能しており、実際の破損例はほぼゼロです。故障が発生してライン全体が止まる前に、部品は交換されるからです。
そのため、IoTのデータ活用においては「実際に致命的な故障が発生する前に、わずかな異常動作の兆候を検知・予測すること」が重要になります。
この「正常データしか手元にない」状況下で、いかにして故障の予兆を捉えるか。
具体的なアルゴリズムとノーコードでの実装手法については、後編で詳しく解説します。
▼ KNIMEで実装する異常検知
ノーコード分析ツール「KNIME Analytics Platform」を使えば、複雑な異常検知モデルもGUI操作だけで構築可能です。
- 具体的な手法を知りたい方へ:
【後編】IoT異常検知のアルゴリズム|オートエンコーダ・統計的手法の実装 - 実際のワークフローを見たい方へ:
異常検知(Anomaly Detection)のサンプルワークフロー (KNIME Hub) - 製造業での導入事例を知りたい方へ:
生産工場での異常検出 活用事例